
Adore__
[Paper Review] A novel application of deep learning for single-lead ECG classification 본문
[Paper Review] A novel application of deep learning for single-lead ECG classification
3_GreenHeart 2023. 4. 3. 13:20(인턴 기간 2022.3 ~ 진행중)
덴마크에서 교수님 밑에서 intern으로 project에 참여하면서 필요한 논문들을 읽고 정리한 것이다.
포스팅 하면서 공부도 해야지!
"A novel application of deep learning for single-lead ECG classification"
Sherin M Mathews 1, Chandra Kambhamettu 2, Kenneth E Barner 3
source: https://pubmed.ncbi.nlm.nih.gov/29886261/
_들어가기 전! ECG 알아보기
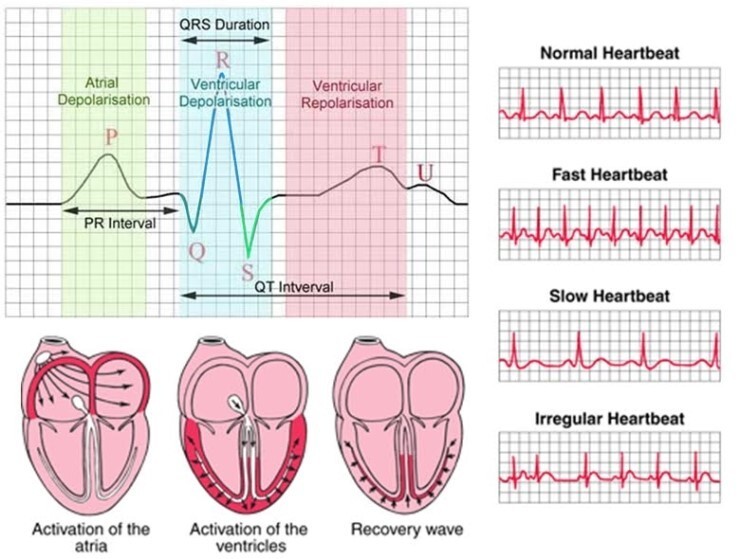
영어라서 생소하게 느껴지지만, 사실 중딩? 고딩때 생물시간에 심장 단원에서 배웠던 심전도의 탈분극, 분극, 재분극 그래프이다..!

위 그림은, 심장박동 1회에 해당하는 ECG 그래프이다.
첫 시작점은 P wave(P파)이고 이후 QRS 구간과 T wave 및 U wave 구간이 난타난다.
심전도의 파형은 심장의 전기적 활동으로 인해 나타나게 되는데, 기본적으로 P wave, QRS complex, T wave 이 3가지의 파형이 있다.
그리고 구간(또는 간격)으로는 PR interval, ST segment, QT interval 가 있다.
* deporlarisation : 감극, 심장이 수축할 때 나타남
* re-polarisation : 재분극, 심장이 이완할 때 나타남
< 파형, 구간 Detail >
1. P wave
: 심방 탈분극시 나타나는 파형으로 오른쪽에서 왼쪽, 그리고 아랫방향으로의 전기적 자극의 전도로 인해 발생한다.
- QRS complex 앞에 위치
- 심전도 그래프에서 2~3mm 정도 (그래프의 2~3개의 작은 사각형 높이)
- 0.006~0.12초 동안 지속 (1.5~3개의 작은 사각현 너비)
- 둥글고 살짝 튀어나와 있는 모양
2. QTS complex
: 심실의 탈분극을 의미하며 전기 자극이 방전될 때 나타나는 파형으로, 위로 솟은 모양이다. 이는 AV junction(심방 연결지점)에서부터 Purkinje Fibres (푸르킨예 섬유) 까지의 정상적인 전도과정을 의미한다.
- PR interval 다음으로 형성
- 5~30 mm 정도의 높이 : 너무 높으면 심근 비대증 의심 / 너무 짧으면 심부전, 비만의 경우
- 0.08~0.12초 동안 지속 : 이 구간이 너무 넓으면 전기전도 지연 및 차단을 의미 / notched QRS complex 모양이면 심장에서 대체 경로가 있음을 의미
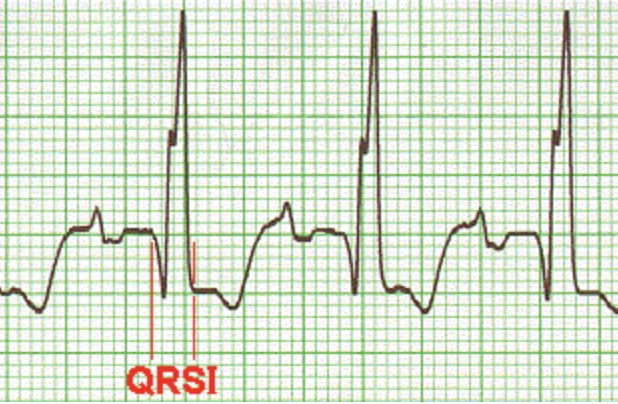
3. ST segment
: 심실 전도의 마지막, 재탈분극의 시작에 발생한다.
- S 파부터 T 파의 시작점까지 연장된다.
- isoelectric line 이다.
- ST segment depression(구간이 아래로 쳐저 있음)이 보일 경우에는 심근 허열증, 심실 비대증을 의심해 볼 수 있다.
- widespread saddle-shaped ST segment elevation (넓게 퍼지거나 움푹 파임)이 나타날 경우 좌심실 동맥류, 협심증을 의심해 볼 수 있다.
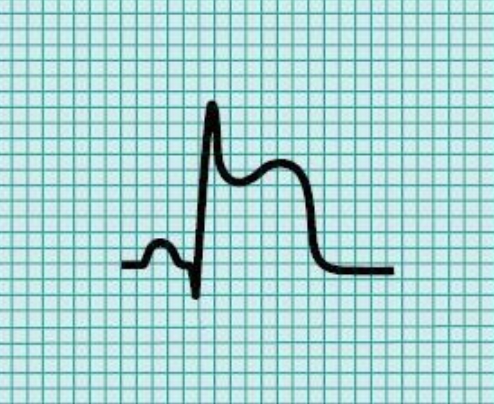
4. T wave
: 심실 탈분극 시 나타나는 파형
- S 파 다음으로 나타난다.
- 둥글고 부드러운 모형이고, 보통 위로 솟아있다.
- QRS complex의 절반 이상 높이를 넘기지 않는다.
- 비정상적으로 높게 나타날 경우, 고칼륨혈증, 급성 심근경색을 의심해 볼 수 있다.
_ABSTRACT
cardiac arrhythmias를 감지하고 분류하는 것은 심장 환자 진단에 매우 중요하다.
이 논문에서는 single-lead ECG 신호를 Deep learning 방법으로 분류하는 새로운 접근 방식을 보여준다.
여기서 사용된 DL은 RBM(Restricted Boltzman Machine) 과 DBN (Deep Belief Networks)로, single-lead ECG를 이용하여 ventricular(심실) 과 supraventricular(상심실성) heartbeats를 감지한다. 여기서 ECG 신호는 MIT-BIH database에서 가져온다.
* cardiac arrhythmias = 심전도, 즉 심장 박동의 불규칙성을 띄는 심부정맥
* venticular = 심실
* supraventicular = 상심실성 ; 심실의 상단에서 발생함
Simulation을 돌린 결과, 적절한 parameter를 설정한 경우 RBM과 DBN은 114Hz의 낮은 sampling rate에서 venticular ectopic beats에 대해 93.6%, supraventricular ectopic beats에는 95.57%의 높은 평균 인식 정확도를 보였다.
* ectopic beats = premature contraction = extrasystole ; 이전의 정상 cardiac cycle 보다 먼저 발생하는 박동.
venticular ectopic beats = venticular premature contraction (VPC)
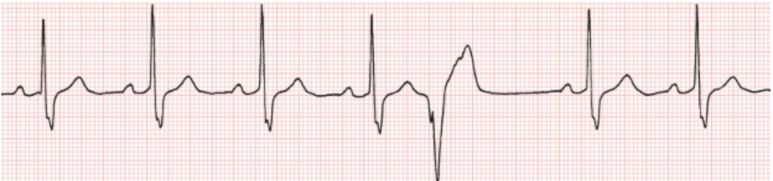
- 5번째 beat가 ectopic beat이다. (ectopic beat와 바로 전의 normal beat 사이의 간격은 normal beat 사이의 간격보다 짧다)
- wide QRS가 관찰된다.
- QRS는, 심전도에서 심실의 수축(탈분극)을 나타내는 파형이다. 이는 심방의 수축을 일으키는 P wave 뒤쪽에 나타난다.
- 보통 QRS파는 0.06 sec - 0.12sec 길이로, 한칸이 0.04sec인 작은 한칸을 기준으로 1칸반 ~ 3칸 이내의 길이를 띄지만, 3칸을 넘어갈 경우 wide QRS라고 부른다. 이 뜻은 심실의 수축에서 이완까지의 간격(탈분극 시간)이 길어진다는 것을 의미하는데, 전기신호가 다른 곳에서 만들어지거나, 심방에서 심실로 추가적인 전도로가 생겼을 때, 심실로 전달되는 전도로가 막혔을 때에 생겨날 수 있다.
- 이처럼 5번째 beat에서는 wide QRS가 보이고 P wave가 관찰되지 않는 것으로 보아, 심실에서 발생하는 VPC임을 알 수 있다.
이 Deep Learning 방법은 전통적인 방식과 비교했을 때, 낮은 sampling rate과 simple features만으로도 최첨단 성능을 이룬 모델임을 보여줬다.
또한 이는 정확한 ECG 분류 뿐만 아니라 arterial blood pressure (ABP), nerve conduction (EMG), heart rate variability (HRV) 와 같은 physiological 신호 분류에도 사용될 가능성을 보인다.
_INTRODUCTION
< Motication of Deep Learning for ECG classification >
심부정맥은 MI (Myocardial infarction, 심근경색) 에서 회복 중인 환자에게 큰 위협이다.
* 심근경색 : 심장 근육이 관상동맥으로부터 혈액을 공급받지 못해 괴사하는 질환. 우리가 흔히 아는 심장마비는 이 심근경색의 증상 중 하나.
몇몇 부정맥은 치명적이고 죽음을 일으킬 수 있기 때문에, ECG 패턴의 조기 자동 감지와 분류는 이런 케이스의 환자들에게 매우 중요하다.
[ 예전 방식들 ]
- Feature extraction methods
: wave shape funtions / Hermite functions / wavelet-based features / frequency-based features / ECG morphology / hermite polynomials / higher order cumulant features / statistical features / Karhunen-Loeve expansion.
- 이러한 extracted features을 분류하는 방법, 분류기
: SVM(support vector machine), KNN, Decision Trees, Artificial Neural Networks, Linear discriminants, Active learning framework, Back propagation Neural Networks.
하지만 이러한 자동 ECG 인식 시스템은 ECG 신호를 일련의 확률적 패턴으로 나타내는 pattern-matching framework에 의존하는 경우가 많기때문에, 복잡한 feature extraction process와 높은 샘플링 속도가 필요하다.
결국, 합리적인 비용으로 실시간으로 구현하려면 이러한 시스템은 간단한 기능과 더 낮은 샘플링 속도를 사용하는 분류 방법을 선택해야 한다.
[ Machine Learning 방식의 한계 ]
- supervised trained dataset에 높은 의존성
- 모르는 ECG records를 다룰 때 성능이 떨어진다.
- 차원 축소 알고리즘과 결합할 때 transform domains에서 complex features을 추출하면 전체 프로세스의 계산 복잡성이 크게 높아진다.
즉, 복잡한 feature-extraction framework를 사용하는 것이 큰 한계다.
실제로 프로젝트를 진행하면서 feature-extraction과 feature selection 하는 데에만 시간 투자를 엄청 해서 애먹었다...ㅠ
feature extraction 이외에도 feature selection, Balancing (undersampling, oversampling), Scaling (StandardScaler 같은) 등, 할 게 너무 많다...
[ 새로운 기술, Deep Learning ]
- ML과 달리 unsupervised feature learning 이다.
- 객체 인식 (object recognition), image verification , classification, speech recognition에 성공적으로 사용되고 있다.
- staced autoencoders를 사용하여 매우 추상적인 표현도 가능하다.
_Methodology
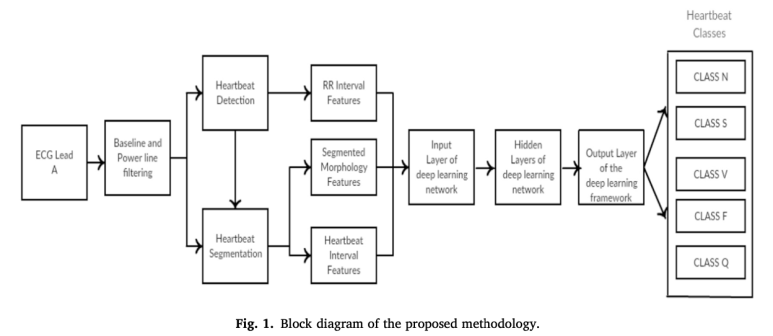
Pattern recognition system은 신호에서 추출된 features을 분석하여 자동적으로 input signal을 class label 에 mapping하는 framework를 제공한다.
이 시스템에서 상징적인 두 단계는 feature extraction 과 classification이다.
feature extraction 전에 data는 pre-processing( filtering과 같은), detection과 segmentation을 거친다.
그리고 나서 feature extraction은 mathematical 기술을 이용하여 알려진 모델과의 연관성을 쌓고 숨겨진 신호의 특성을 활용하여 데이터를 가장 잘 구별할 수 있는 표현들을 얻는다.
- Pre-processing
먼저, 각 ECG 신호는 0.11Hz에서 필터링되고 360Hz에서 샘플링된다.
* Hz : 1초에 한번 진동함. 즉, 100Hz는 1초에 100번 진동하는 것
preprocessing으로 baseline wander, power-line interference, high frequency noise, motion artifacts와 같은 artifacts(인공물)를 제거한다.
* artifact : 인공물
- Baseline wander
- 원인 : Baseline wander는 빈번한 artifacts는 아닌데, 기침이나 가슴을 크게 움직이는 호흡으로 인해 cheast-lead ECG 신호가 방해 받을 때, 피부접촉 불량 전극이나, 팔과 다리의 움직임으로 인해 limb-lead ECG 신호가 방해 받을 때 발생할 수 있다.
- 제거 방법 : window 크기가 200ms와 600ms 인 median filter에 신호를 전달 해서 P waves, QRS complexes, T waves가 제거된다.
- Power - line interference
이는 50 Hz의 정수 배수에서 주파수를 가지는 간섭 전압 (interference voltage)인데, 이는 ECG 파형을 완전히 애매하게 만들어 버릴 수 있다.
- 원인 : 부적절한 grounding(접지; 전기 기기와 지면을 동선 등의 도선으로 연결하는 것), 환자의 케이블에 느슨하게 접촉했을 때, 전극(electrode)이 분리되었을 때 나타난다
* stem from: ~로부터 일어나다
- Power line interference & high frequency noise 제거 방법: 12탭 low-pass filter와 finite impulse response filter를 사용하는 baseline이 보정된ECG에서 제거된다. 여기서 유한 impulse 응답 필터는 35Hz에서 3dB을 가지고, 통과 및 정지 bands 모두에서 동일한 Ripple을 갖는다.
( Ripple이 뭔지 저 두 필터가 뭔지 모르겠다... 그래서 찾아봤다!!!)
- Motion artifacts
이는 전극의 움직임으로 인한 electrode skin impedance(교류회로에 있어서 전기 저항의 총칭)으로 유도되는 일시적인 baseline interference이다.
이 artifacts의 peak amplitude(진폭)은 peak-to-peak ECG 진폭의 500%이고 지속 시간이 약 100–500ms이기 때문에 ECG 파형을 흐리게 하여 해석하기 어렵게 만든다.
- 제거 방법: RLS (Recursive Least Square) 알고리즘을 이용하여 adaptive filter로 제거한다. Spectrograms 와 convergence plots 을 보았을 때, RLS 알고리즘이 LMS(Least Mean Squares) 알고리즘과 비교할 때 ECG 신호에서 모션 인공물을 제거하는 데 더 효율적이다.
따라서 지속적으로 변화하는 신호에 따라 filter coefficient(계수)를 변경하는 적응형 필터로 Motion artifacts를 제거하는 방법을 택했다. 여기서 filter 계수를 변경 할 때 adaptive 알고리즘을 사용하는데, 이는 ECG와 같은 non-stationary(비정상 신호; 시간에 따라 통계적 특성이 변함)에 대한 최적의 noise 제거 기능을 가진다.
* impedence : 교류회로에 있어서 전기 저항의 총칭
* amplitude : 진폭
* adaptive filter : feedback 을 통해서 filter coefficient 를 계속해서 update 해 나가는 시스템.
* RLS 알고리즘
* LMS 알고리즘
2. Processing: heart beat detection and segmentation
2.1 HeartBeat detection
심장박동 감지는 input sampling 속도인 360 Hz에 비해 낮은 114Hz sampling 속도에서 이루어진다. 이 논문에서는 ECG detection algorithm 으로 filterbank 방식을 따랐는데, 여기서 Filterbanks subbands는 다운샘플링되고 feature 계산, MWI, 피크 검출기와 같은 one-channel detection block의 구성요소는 ECG의 input sampling rate 보다 낮은 속도에서 작동된다. 이러한 Filter bank를 사용함으로서 여러 주파수 대역을 매우 효율적으로 분석할 수 있다.
* Filter bank
....
이후 과정은 물리학적인 부분이 너무 많고 우리 프로젝트에서는 이미 주어진 데이터를 사용하기 때문에 생략하겠다..
....
3. Feature extraction
114 Hz에서 ECG 신호들을 down-sampling한 후에, 두가지 feature extraction 방법을 사용했다.
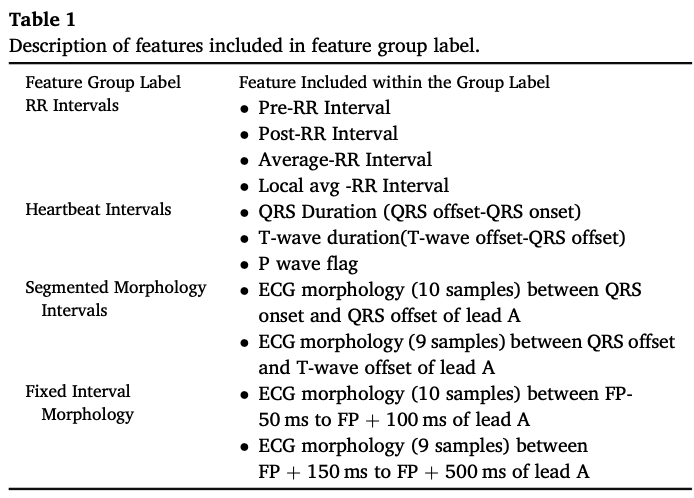
Feature set 1 (FS1) 은 RR intervals, heart-beat intervals, segmented morphology(형태,구조)로 구성된 (comprise) 26개의 features를 만들었다.
Feature set 2 (FS2) 는RR intervals 와 고정된 interval 형태로 이루어진 22개의 features를 만들었다.
이 논문에서는 single-lead feature extraction 방법으로 결정했는데 (settle upon), 이 방법은 샘플링 속도가 낮고 feature vector가 작아서 전력 소비를 줄이고 하드웨어 복잡성을 낮추기 때문이다.
* comprise : 포함되다, 구성되다
* morphology : 형태, 구조
* settle upon : ~로 결정하다
3.1 Feature set 1
앞에서 언급했듯이, 다음과 같은 3가지를 포함한 26가지 features로 이루어져 있다.
- RR intervals features
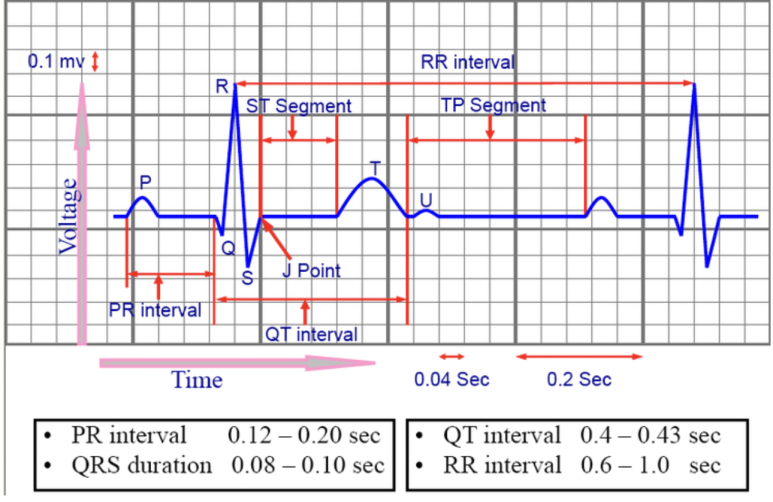
정상 ECG의 RR interval
RR intervals 는 Heartbeat fiducial point intervals 라고도 하는데, 그 다음에 이어지는 heartbeat fiducial points(심장박동 기준점) 와 상응한다.
* fiducial : 기준의, fiducial point : 기준점
* successive = consecutive : 연이은, 연속적인
다음 4가지 특성들이 RR intervals에서 추출된다.
1) Pre-RR interval : 주어진 심장박동과 그 이전 심박 사이 간격인 RR interval
2) Post-RR interval : 주어진 심박과 다음 심박 사이의 RR interval
3) Average RR interval : 기록된 RR interval의 평균. 이 값은 모든 기록된 심박에 대해서 동일하게 유지된다.
4) Local average RR interval : 심박에 둘러쌓인 10개의 RR interval들을 평균내서 측정한 값.
- Heartbeat interval features
3가지 특성이 post-heartbeat interval segmentation에서 추출된다.
1) QRS duration : QRS onset 과 offset 사이의 시간 간격
* onset : 개시
* offset : 상쇄
2) T-wave duration : QRS offset 과 T-wave offset 사이의 시간 간격
3) Boolean variable : P-wave의 유무를 알려주는 3번째 변수
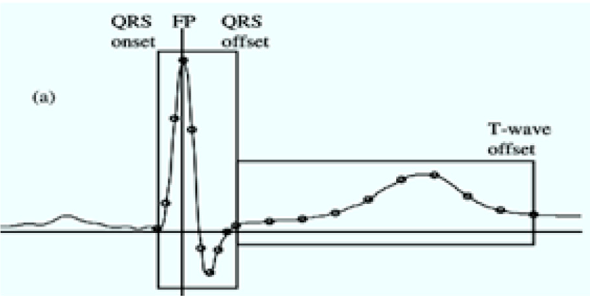
- Segmented morphology interval features
Segmented morphology(분할된 형태)는 ECG 신호의 진폭 값을 포함하는데, 이 값은 'QRS onset과 offset 사이'의 샘플링 창과 'QRS offset과 T-wave offset 지점 사이'의 샘플링 창에 의해 계산된다. 기준점(FP)을 결정한 후 두 개의 샘플링 windows를 사용했다.
* encompass : 포함하다
- the first window : QRS onset ~ offset
- the second window : QRS offset ~ T-파장 offset
10개의 균일한 간격의 sample 특징들은 첫번째 창에서 ECG 증폭을 균등하게 샘플링하여 얻어냈고, 추가적으로 9개는 두번째 창에서 균등하게 샘프링하여 얻어냈다. 이로서 총 19개의 특징들이 나왔다.
* evenly : 고르게, 공평하게
3.2 Feature set 2
FS2의 22개 특징들은 크게 2가지 종류들로 이루어져있다.
- RR interval features
: 앞에 FS1에서와 동일하게 4개의 특징들이 나온다.
- Fixed-interval morphology features
: 이 고정된 interval 형태를 결정하기 위해서는, 먼저 심박 FP(기준점)에서 sampling windows를 잡는다. 두개의 샘플링 창은 FP에 따라서 만들어진다.
- the first window : 대체로 QRS complex를 포함하고 FP-50ms와 100ms 사이의 ECG를 커버한다. 여기서 9개의 샘플이 추출된다.
- the second window : 대체로 T-wave를 커버하고 150 ms에서 시작하여 500 ms에서 끝난다. 추가로 여기서 9개의 샘플이 추출된다.
여기서는 FS1의 segmented morphology와 다르게 window 출발점과 끝점이 고정되어 있어서 이름이 fixed interval 인 것으로 이해했다.
최종적으로 정리해보면 다음과 같다.
FS1 (26개) : RR intervals (4) + heartbeat intervals (3) + segmented morphology (19)
FS2 (22개) : RR intervals (4) + fixed interval morphology (18)
이러한 feature sets 를 정의하기 위해 광범위한 통계적 가설 테스트 실험이 수행되었다.
가설 테스트 결과, segmented morphology features, heartbeat interval feature 및 RR interval feature (FS1 특징들)이 VEB 및 non-arrhythmia (비-부정맥) 클래스와 비교하여 SVEB 부정맥 사례에 대해 크게 변화하였다.
* VEB : 심실 이소성 박동 ; 심실에서 나타나는 이소성 박동
* SVEB : 심실 위 이소성 박동 ; 심실 위쪽에서 나타나는 이소성 박동
* 이소성 박동 : 이소성 박동이란 정상적인 심장박동 이후에 불규칙하게 한 번씩 나타나는 심장박동. 심방, 심실 어디서나 발생할 수 있다.
이 3가지 features은 SVEB와 나머지 class를 구별하는데 안정성을 나타내어 feature set 1로 정했다. 또한 fixed interval morphology 와 RR interval은VEB 부정맥 sample에서 크게 바뀌어서 feature set 2를 구성했다.
가설 검정 외에도 pair-wise correlation(쌍대 상관)을 포함하는 multi-collinearity test (다중 공선성 검정)을 수행했다. paired t-test에서 예측 변수가 모델의 다른 예측 변수와 상관 관계가 없다는 것을 확인했고, 이로서 multi-collinearity가 RBM-DBM model에서 문제가 되지 않는 다는 것을 확인했다.
* robustness : 견고함, 튼튼함
* constitute : 구성하다 ( consist of = ~ 로 구성되어 있다)
* extensive : 광범위한
* arrhythmia 부정맥
* collinearity : 공선성, 같은 선 상에 있음
* multi-collinearity test
전체 기능 세트는 다음과 같이 요약할 수 있다.
_DEEP LEARNING FRAMEWORK
- Restricted Boltzmann Machine (RBM)
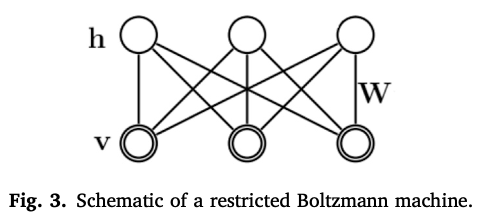
Boltzmann Machine은 DNN, CNN 과 같은 Deterministic Model과 달리 Generative Model이다.
Deterministic Model은 타겟과 가설 간의 차이를 줄여서 오차를 줄이는 것을 목표로 하지만, Generative Model은 확률밀도함수를 모델링 하는 것을 목표로 한다. 즉, Boltzmann Machine은 확률분포(정확히는 확률질량함수 혹은 확률밀도함수)를 학습하기 위해 만들어졌으며, 이 모델이 가정하는 것은 “우리가 보고 있는 것들 외에도 보이지 않는 요소들까지 잘 포함시켜 학습할 수 있다면, 확률분포를 좀 더 정확하게 알 수 있지 않을까?”라는 것이다.
RBM은 Boltzmann Machine에서 나온건데, 이는 해당 분포에서 샘플들을 기반하여 알려지지 않은 확률 분포의 중요한 features을 학습하는 확률적 처리 장치의 양방향 연결 네트워크이다. RBM은 visible layer와 hidden layer 이 두가지를 가진 bipartite graph로 설명할 수 있다.
< RBM Bipartite Graph + weight matrix >
- Visible layer : 입력 데이터가 들어가는 곳. units (Fig 3.에서 원 모양)은 일반적으로 베르누이나 가우시안 분포를 따른다
- Hidden layer : 은닉 데이터가 샘플링되어 나오는 곳. units은 일반적으로 베르누이 분포를 따른다.
- Weight matrix : 이 두개의 층을 연결해 주는 장치.
visible layer의 확률 단위들은 hidden layer의 확률단위와 연결되어 있는데, weight matrix의 평균들이 이들을 연결한다.
> 이로서 visible layer의 데이터가 주어졌을 때, hidden layer의 데이터를 계산할 수 있도록 하거나 혹은 그 반대의 경우 계산할 수 있도록 하는 '조건부 확률'을 구할 수 있다.
하지만 같은 layer의 내부적인 연결은 없다.
> 이는 사건 간의 독립성을 가정함으로써 확률분포의 결합을 쉽게 표현하기 위해서라고 한다.
설계도를 보면, 이 그래프의 각 끝점은 가중치(대칭 행렬 W로 표기됨)에 붙어있고, 이 가중치는 visible layer(v)와 hidden layer(h)와 연관되어 있다.
주어진 RBM 은 visible 과 hidden state 벡터들의 모든 구성들에 대한 에너지 함수를 정의한다. 만약 v 와 h 모두가 binary states (이진 상태, 즉 베르누이-베르누이 RBM)일 경우, 에너지 함수는 다음과 같다.
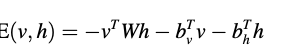
따라서, RBM은 visible unit v와 hidden random unit h 간의 joint 분포 p(v;h)를 보여준다.
joint 확률은 다음과 같다.
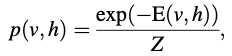
여기서 Z는 partition 함수로, 다음과 같다.
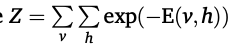
원래 Boltzmann Machine은 p(v,h)를 계산하지만, 이 과정은 상당히 어렵기 때문에 그대신 RBM에서는 p(h|v)나 p(v|h)를 구하는 것이다.
즉, Boltzmann Machine에서 RBM과 같은 형태를 가지면서 생기는 특징은 Feed-Forward Neural Network(FFNN)처럼 학습하게 된다는 점이다.
( forward propagation을 통해 hidden unit 상태를 결정하게, 다시 hidden unit 상태로부터 back propagation함으로써 visible unit의 상태를 재결정 함)
* schematic : 개요의, 도식적인 / 설계도, 구성도
* stochastic : 확률적
* bipartite : 2 부분으로 나뉜
* symmetric : 대칭적인
* weight matrix : 가중치 행렬 ; 가중치는 훈련되는 parameter로, 훈련 데이터를 신경망에 노출시켜 학습된 정보가 담겨져 있는 것이다. 초기에는 작은 난수로 채워져 있지만, 피드백 신호에 기초하여 가중치가 점진적으로 조정된다. (점진적 조정 = 훈련 = 머신러닝에서의 '학습'). 이 가중치들이 변함에 따라 데이터의 특성을 더 잘 추출하고 더 잘 예측하게 되는 것이다.
사실 중간에 점점 무슨 소리인지 모르겠어서 그냥 따로 찾아봤다.
Restricted Boltzmann Machine - 공돌이의 수학정리노트
angeloyeo.github.io

이 포스팅을 참고했다.
아무래도 이 모델은 따로 포스팅을 해야겠다.
우선은 이 모델로 확률분포를 정확히 학습함으로서 좋은 sample을 샘플링하여 결과물을 생성하는 것으로 이해했다.
2. Deep Belief Networks (DBN)
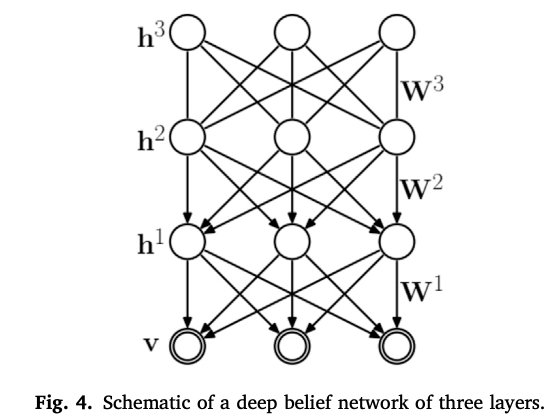
DBN은 일종의 다층 생성 신경망(multi-GNN)으로서, 높은 수준으로 학습된 feature들을 모델링하고 시각화한다.
DBN은 stacked, logistic RBMs 이 두가지로 구성되어 있는데, 이는 lowest-level RBM이 데이터의 shallow(얕은) model을 학습하고, 그 다음 수준의 RBM이 first-layer hidden units을 모델링 하는 방법을 학습한다. 따라서 계층적 구조를 통해 높은 수준의 추상적 표현이 가능하다.
DBN이 분류 목적으로 사용되는 경우, 심층 신경망의 가중치는 RBM의 pre-training(선행학습)으로 초기화되고 역전파 오류 도함수에 의해 판별적으로 미세 조정될 수 있다. DBN의 recognition 가중치는 표준 신경망의 가중치가 된다. 이러한 비지도 선행학습은 최종 학습 단계를 위한 절차인 미세 조정 단계(경사하강법 최적화를 기반으로 하는 지도학습 기준에 관한)를 설정한다.
* discriminatively 구별되게, 차이 나게
* derivative : 유도된 / 도함수
* with respect to : ~에 관하여
* criterion : 기준 = standard
_EVALUATION OF PROPOSED METHODOLOGY
1. The MIT-BIH Database
2. AAMI standard
의료진흥협회 (AAMI) 기준에 관한 것
이 논문에서는 AAMI 권장 사례를 사용하여 MIT-BIH heartbeat types을 다음과 같은 5가지 class로 분류했다. (이 class가 label이 되는 것이다)
1) Class N : sinus node 에서 발생하는 beat ( 정상 박동 유형)
2) Class S : 상심실 이소성 박동 (SVEB)에 해당
3) Class V : 심실 이소성 박동 (VEB)에 해당
4) Class F : 정상박동과 VEB이 합쳐진 beat
5) Class Q : paced beat를 포함하여 알 수 없는 beat에 해당

3. Evaluation metrics
- 첫 번째 데이터 세트(DS1)(train set) : 분류기를 훈련하고 분류기의 성능을 최적화하는 매개변수 값을 설정하는 데 사용됨
- 두 번째 데이터 세트(DS2)(test set) : 이를 이용하여 심장 박동 분류 시스템의 독립적이고 편향되지 않은 성능 평가 수행
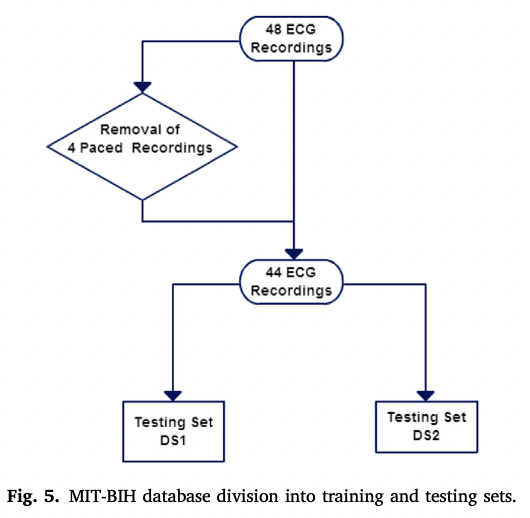
제안된 framework의 최종 목적은 두개의 치명적인 비정상 박동, SVEB와 VEB를 효과적으로 분류하는 것이다.
MIT-BIH dB에 대한 알고리즘의 성능을 평가하기 위해서 정확도(Ac), 민감도(Se), Positive predictive value (PPV), False positive rate(FPR), 이 네가지 성능 metrics를 사용했다.
4. Experimental results and Discussion
360 Hz, 114 Hz 두가지 sampling 속도에서 얻은 샘플을 이용하여 train과 Test를 한 후, 다음과 같은 결과를 얻었다.
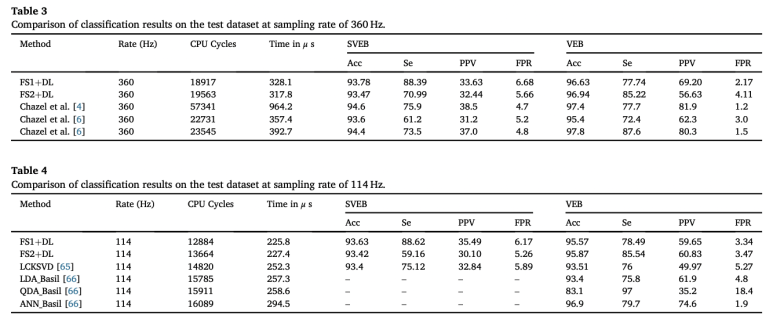
보면 360, 114 Hz 모두에서 높은 정확도를 보인다.
이 두가지 속도 이외에 다른 속도에서도 결과를 내보았는데, 다음과 같은 그래프를 그린다.
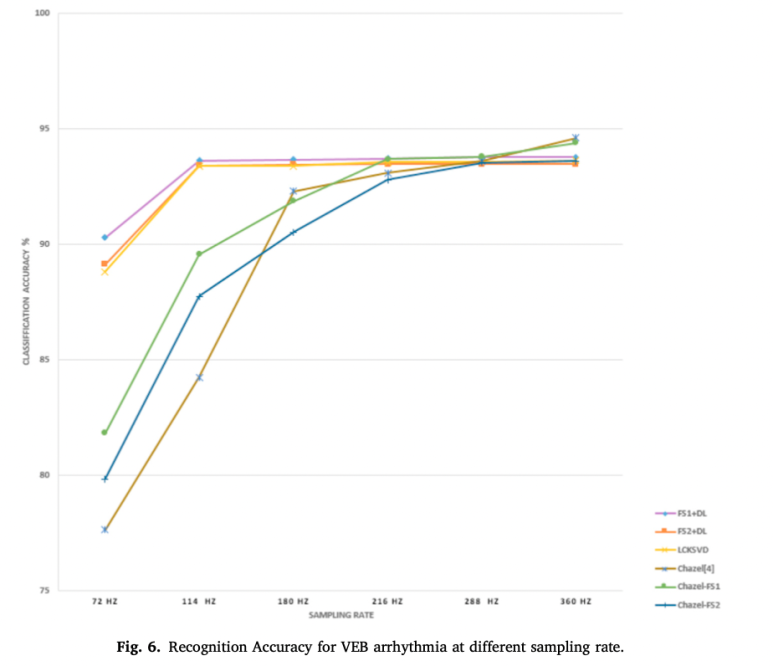
하지만 다양한 샘플링 속도는 성능에 아주 미미한 영향을 주기때문에, 실험에서 사용된 model이 낮은 샘플링 속도에서도 높은 성능을 보였다는 것으로 결론지을 수 있다.
성능평가 matrix로 다음과 같은 Confusion Matrix도 보고했다.
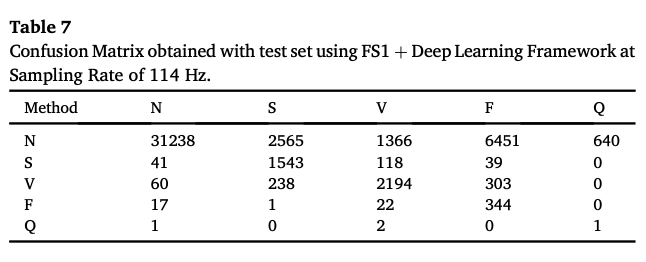
현재 진행하고 있는 Project 코드 짤 때에 지금 다루고 있는 데이터에 관한 지식과 Class별 의미, 그리고 성능평가 matrix로 무엇을 사용해야하는지 좋은 참고가 되었다.
이외에 다양한 DL 알고리즘이 나와서 조사하는데 시간이 오래 걸렸지만, DNN 알고리즘을 다시 한번 정리해야겠다는 자각을 심어준 것 같다...ㅎ