
Adore__
[Do it!_Algorithm with Python] 1.정렬 본문
Source : Inflearn - 'Do it! 알고리즘 코딩테스트 파이썬'
정렬의 종류는 버블, 선택, 삽입, 퀵, 병합, 기수 총 6가지가 있다.
Bubble sort
▪️특징
- 인접한 데이터의 크기를 비교해서 정렬하는 방법이다.
- 시간 복잡도가 O(n^2)으로, 다른 정렬 알고리즘에 비해 느리다.
▪️방법

첫번째 원소부터 인접한 원소와 크기를 비교한다. 만약 i+1 원소보다 i 원소가 더 크면, 둘이 순서를 바꿔준다.
이렇게 1번부터 N번까지 돌아가면서 바꿔주다보면, 가장 마지막원소는 가장 큰 원소가 된다.
이게 1번의 루프이다.
위 그림에서 파란색 박스는 이미 정렬된 데이터로, 다음 루프에서는 제외된다.
루트 한번을 돌 때는, 모든 원소들을 하나하나 체크해가며 순서를 바꿔야 하기때문에 n번 돌게 된다 (1번 루트에 n번)
하지만, 이 하나의 루트를 각 원소마다 돌아야하므로, nxn, 총 n^2번을 돌게 된다. (n번 루트는 n^2 번)
단, 여기서 만약 루트를 돌면서 한번도 자리바꿈 (swap)이 없었다면, 그 영역 뒤에 있는 모든 데이터는 정렬된 상태이므로 프로세스를 종료하게 된다.
Selection Sort
선택정렬은 데이터가 나열된 순서대로 최대 or 최소 값을 선택하면서 찾는 방법이다.
마찬가지로 시간복잡도가 O(n^2)이기때문에 잘 사용하지는 않는다. 원리 정도만 짚고 넘어가자.

처음 시작할때는 첫번째원소부터 끝까지 쭉 돌아보며 최소값을 찾아 맨 앞으로 끌어온다. (위 그림에서는 15)
그리고 2번째로 넘어가 반복한다. (24) 이렇게 해서 마지막 원소까지 돌면 오름차순으로 정렬된다.
1) 남은 정렬 부분에서 minimum or max 값을 찾아 선택!
2) 남은 정렬 부분의 가장 앞에 있는 값과 선택했던 값을 swap!
3) 다음 루프로 넘어가기 위해 가장 앞에 있는 데이터의 index 값을 1 더해주면서 이동한다. (index ++)
4) 전체 데이터 크기만큼 index가 커질 때까지 (남은 정렬 부분 없어질때까지) 반복한다.
🔻 시간 복잡도가 왜 n^2일까?
첫번째 loop를 보면, 최소값을 찾기 위해서 n번 돌아야한다. ( 한번 Loop 도는데 n번)
그리고 남은 정렬부분을 줄여가면서 index를 키워갈때, 마찬가지로 n번 이동하면서 검사해야하기때문에 nxn이 된다.
Insertion Sort
삽입정렬은 이미 정렬된 데이터 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입시켜서 정렬하는 방법이다.
이 또한 시간복잡도가 O(n^2)이지만, 구현하기가 쉽다.

먼저 데이터 하나를 선택하고, 그 앞에 있는 원소를 하나하나씩 비교하면서 자신이 들어갈 자리를 고른다.
24의 경우, 42보다 작으니까 왼쪽으로 가야한다. 또 32와 비교했을 때 작으므로 최종적으로 32 왼쪽에 들어가게 된다.
이때 42와 32는 한칸씩 오른쪽으로 이동해야 24가 들어갈 수 있다.
1) 현재 index에 있는 데이터 값을 선택한다. -> 정렬되지 않은 남은 부분에서 가장 첫번째가 현재 index가 된다.
2) 현재 선택한 데이터가 정렬된 범위에서 들어갈 위치를 찾는다. -> 정렬된 부분 (왼쪽)에서 값을 비교하면서 자신보다 작은 원소가 있을 때까지 탐색하고 그 바로 오른쪽을 들어갈 자리고 결정한다. (오름차순일 경우)
3) 이제 선택했던 그 자리에서 현재 있는 자리 사이의 원소들을 한칸씩 오른쪽으로 이동해주어야 한다. 그래야 원하는 자리에 빈 공간이 생겨 들어갈 수 있기때문이다. (선택한 삽입 위치부터 현재 index 위치까지 shift 연산 수행)
4) 위 과정을 계속 반복하고, 정렬된 범위가 점점 넓어져서 현재 index가 전체 데이터 크기만큼까지 가게 되면 멈춘다.
내가 들어갈 자리를 탐색할 때 최악의 경우, 아래 그림과 같이 N번만큼 돌리게 된다.

이를 개선한 방법이 binary search이다.
가운데 데이터와 빨간색 데이터를 비교해서 검색할 영역을 반으로 줄여나가면 log n 시간복잡도가 가능하다.
이렇게 빠르게 찾을 수는 있지만, shift 작업 또한 오래 걸리기때문에 실제 코테에서는 잘 사용되지 않는다.

Quick Sort
퀵 정렬은 기준값을 정해서 해당 값보다 작은 데이터와 큰 데이터로 분류하고, 이를 반복하면서 정렬하는 방법이다.
여기서 중요한건 이 '기준값'을 어떻게 결정하느냐 이고, 시간복잡도를 결정하는 요소가 된다.
평균 시간 복잡도는 O(nlogn) , 최악의 경우에는 O(n^2) 이다.

1) 가장 먼저 기준 데이터 pivot을 설정한다.
2) 정해진 pivot을 기준으로 아래 과정을 거친다.
- [ start가 가리키는 값 < pivot 이 가리키는 값 ] 인 경우, start를 오른쪽으로 1칸 이동 (start 값이 클때까지 오른쪽 이동)
- [ end가 가리키는 값 > pivot이 가리키는 값 ] 인 경우, end를 왼쪽으로 1칸 이동 ( end 값이 더 작을때까지 왼쪽으로 이동)
- 이렇게 비교하다가 어느 순간에는 멈춰야 한다. [start 데이터 > pivot 값 / end 값 < pivot 값] 이 둘을 모두 만족할 때, star와 end 가 가리키는 데이터를 서로 바꿔줌 -> 이후 start는 오른 쪽, end는 왼쪽으로 1칸 이동
- start와 end 화살표가 만날 때까지 1~3 까지 반복한다.
- start와 end가 중첩되면 그 데이터와 pivot 데이터를 비교 -> 만약 pivot 데이터가 크면 중첩 지점의 오른쪽, 작으면 왼쪽에 데이터 삽입
3) 분리집합 (그림 마지막 줄에 회색 뭉텅이와 주황색 뭉텅이)에서 각각 다시 pivot 선정
4) 분리집합이 1개 이하가 될때까지 1)~3) 반복
🔻핵심
고정된 pivot을 중심으로 계속 데이터를 2개의 집합으로 나누면서 정렬!
따라서 pivot 하나 기준으로 최악의 상황에서는 start와 end를 N번 움직인다.
그리고 pivot이 원소 개수인 N개만큼 바뀔 수 있으므로, nxn, n^2의 시간 복잡도를 갖게 된다.
이 퀵 정렬은 구현하기 생각보다 어려워서, 꼭 코드로 구현해 보는 것이 필요하다.
🔥 Merge Sort (중요)
병합 정렬은 분할 정복 방식을 사용하여 데이터를 먼저 잘게 분할하고, 이 작은 집합들을 합칠 때 정렬을 동시에 수행하는 알고리즘이다.
시간복잡도는 O(nlogn)으로, 알고리즘 중에 가장 많이 활용된다.
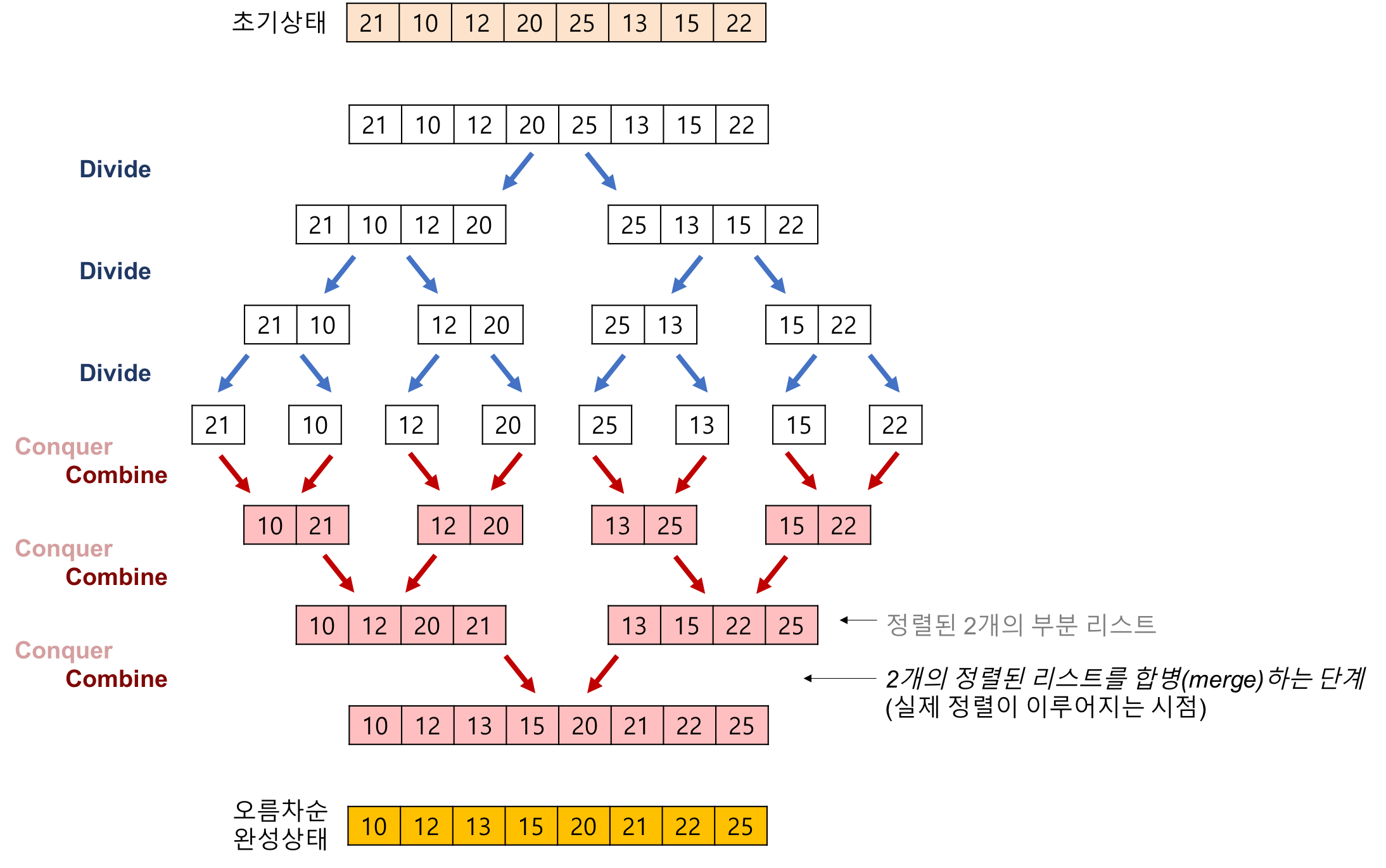
위 그림처럼 원소가 1개가 될때까지 분할하고, 다시 2개의 집합씩 합치면서 정렬해준다.
전체는 정렬이 안되어있지만, 각각의 덩어리는 정렬되어 있는 것이다.
▪️시간 복잡도 nlogn
여기서 시간복잡도가 왜 nlogn일까?
분할 후 병렬된 부분인 빨간 박스들을 보면, 원소의 개수가 8개인데 총 3번만에 정렬이 완료된 것을 볼 수 있다.
한번 합칠때마다 원소의 개수가 2배 불어나고, 2를 3번 곱하면 총 원소 개수인 8개가 되기때문이다.
여기서 바로 logn 이 나온다 (log8 = 3)
그리고 각 process마다 각 소집합의 원소들을 비교하면서 정렬하므로, 총 원소의 개수이 n 번 돌리게 된다. (1 process에 8번)
따라서 시간 복잡도는 ( 8 x log 8 )이다.
▪️2개의 그룹 병합하는 원리

2 pointer 개념을 사용해서 분할되었던 왼쪽 오른쪽 그룹을 병합한다.
1) 왼쪽 그룹의 pointer와, 오른쪽 그룹의 pointer가 가리키는 값을 서로 비교한다 (24 vs 5)
2) 이중 작은 값 (5) 을 결과 배열에 먼저 추가한다
3) 그리고 그 그룹 내 (5가 있었던 오른쪽 그룹)에서 Pointer를 오른쪽으로 1칸 이동한다.
이 과정을 pointer가 끝까지 갈때까지 반복한다.
여기서 보면 최악의 경우,
왼쪽 그룹의 pointer가 한칸씩 계속 이동해서 4번 / 오른쪽 그룹의 pointer가 이동해서 4번 => 총 8번 이동하게 된다.
따라서 위에서 말했던 시간복잡도 nlogn에서 n이 곱해지게 되는 것이다.
▪️응용 : 자동차 추월 문제
위 그림에서 5를 보면, 원래 처음 배열에서는 5번째에 위치해 있었는데, 병합을 하자마자 1번째로 이동한 것을 볼 수 있다.
즉, 앞에있던 4개의 숫자를 앞지른 것이다.
이를 자동차 경주문제로 생각해보면, 몇번의 역전이 일어날까? 를 답할 수 있다.
5위에 있던 자동차 (5번)가 앞에 있던 자동차를 4번 추월하여 1위를 한 것이다. (4번 추월)
다음줄을 보면 6위에 있던 15번 자동차는 2등을 하면서 마찬가지로 4번 추월한다. (4번 추월)
그리고 마지막으로 7위에 있었던 45번 자동차는 6위를 하면서 1번 추월한다 (1번)
결과적으로 병합 정렬을 사용해보면 총 9번 역전이 일어난 것을 구할 수 있다.
Radix sort
기수정렬은 값 자체를 비교하지 않고, 자릿수 하나를 정해서 그 해당 자릿수만 비교하는 알고리즘이다.
시간 복잡도는 O(kn)으로, 여기서 k는 데이터의 자리수를 말한다.
만약 1<=N<=1000000 이고 주어진 숫자가 4자리수(9999) 이면, 시간 복잡도는 4x1000000이 되는 것이다.
이 방법은 병합 정렬처럼 많이 쓰이지는 않지만, 자리수가 작은 경우에는 효과적으로 사용될 수 있다.
▪️핵심
10개의 큐를 이용하는 것이 특징이다. 여기서 각 큐는 값의 자리수가 들어가는 바구니와 같다.
한 자리수에 들어갈 수 있는 수는 0~9이므로, 총 10개의 큐를 이용하는 것이다.

위 그림은 대상 데이터가 2자리수이다.
먼저 일의자리수를 기준으로, 대상 데이터마다 자신의 일의자리수에 맞는 큐에 들어간다.
이때 나온 순서대로 데이터를 정렬하면, 1의자리수 기준으로 오름차순으로 정렬된다.
그리고 이 정렬된 데이터를 다시 10의 자리수 기준으로 반복한다.
결국에 일의자리가 작은 것부터 먼저 들어가고, 두번째 큐를 거치면서 십의자리수 기준으로 정렬된다.
'큐'의 특성상 먼저 들어가는 것이 먼저 나오므로 최종적으로 나온 결과를 보면 오름차순으로 정렬된 것을 볼 수 있다.
기수정렬은 이처럼 시간복잡도가 가장 짧은 정렬이다.
하지만 이렇게 10개의 큐를 만들어서 넣는 것을 코드로 구현하는 것이 상당히 어렵다.
'Basis > Algorithm' 카테고리의 다른 글
| [Do it!_Algorithm with Python] 5.1 그래프 기본/표현 방법 (1) | 2023.04.24 |
|---|---|
| [Do it!_Algorithm with Python] 4.정수론 (0) | 2023.04.24 |
| [Do it!_Algorithm with Python] 3. Greedy Algorithm (0) | 2023.04.22 |
| [Do it!_Algorithm with Python] 2.탐색 (0) | 2023.04.22 |
| [Do it!_Algorithm with Python] 0. Start (0) | 2023.04.21 |


