
Adore__
[BoostCourse DL] Sequential Model - Transformer 본문
Source
- [Attention is All you Need, NLPs, 2017] 논문
- [BoostCourse, '딥러닝 기초다지기']
Transformer
RNN은 하나의 입력이 들어가고 또 다른 입력이 들어올 때, 이전 RNN에서 갖고있던 cell state가 반복해서 돌아가는 재귀적인 구조였다.
반면, Transformer는 재귀적인 구조가 아닌 Attention 구조를 활용한다.
Attention 구조가 무엇인지는 차근차근 알아보자.
먼저 Transformer는 sequential data를 처리하고 encoding 하는 구조이기때문에
NLP 뿐만 아니라 이미지 분류, detection, 등 에서도 효과적으로 활용된다.
우리의 목적은 어떤 문장이 주어지면 다른 sequence로 바꾸는 것이다. (ex. 영어 문장 -> 한국 문장)
아래 그림을 보면 입력은 3개의 단어로 되어있고, 출력은 4개의 단어이다.
이를 통해 알 수 있는 점은, 입력과 출력의 domain이 다를 수 있고, 모델은 하나의 모델이라는 것이다.
원래 RNN 같은 경우는 3개의 단어가 들어가면 3번 모델이 돌아간다. 하지만 encoder는 몇개의 단어가 들어가든, 재귀적으로 돌지 않고 한번에 찍어낸다. 즉, 한번에 n개의 단어를 처리할 수 있다.

그렇다면 다음 질문을 떠올려보자.
- n개의 단어가 어떻게 한번에 처리가 될까?
- encoder와 decoder사이에 어떤 정보가 교환될까?
- decoder가 어떻게 generation 할 수 있나?
1) N개의 단어가 어떻게 한번에 처리 될까?
encoder를 보면 N개의 단어가 한번에 들어간다.
하나의 encoder에 들어가면 self attention -> feed forward layer라는 2단을 거친다.
여기서 중요한 것은 self attention layer이다.
NLP 문제를 해결한다고 가정하고 다음을 보자.
3개의 단어가 들어왔다. 기본적으로 각 단어마다 특정 숫자의 벡터로 표현한다.
self attention은 3개의 단어가 주어지면 각 벡터를 찾는다. x1이 z1으로 넘어갈 때, x2와 x3 또한 고려한다.
" I wish my 20s days are full of happiness. It is one of my bucket lists."
이 문장에서 it은 어떤 것을 지시하는지 알아야한다. 즉, 그 문장속에서 다른 단어들과의 interaction을 알아야한다.
it을 encoding할 때 다른 단어들과의 관계성을 보게 된다.
하나의 단어가 주어졌을 때, 3가지 벡터를 만든다. Query, Key, Value 이다.
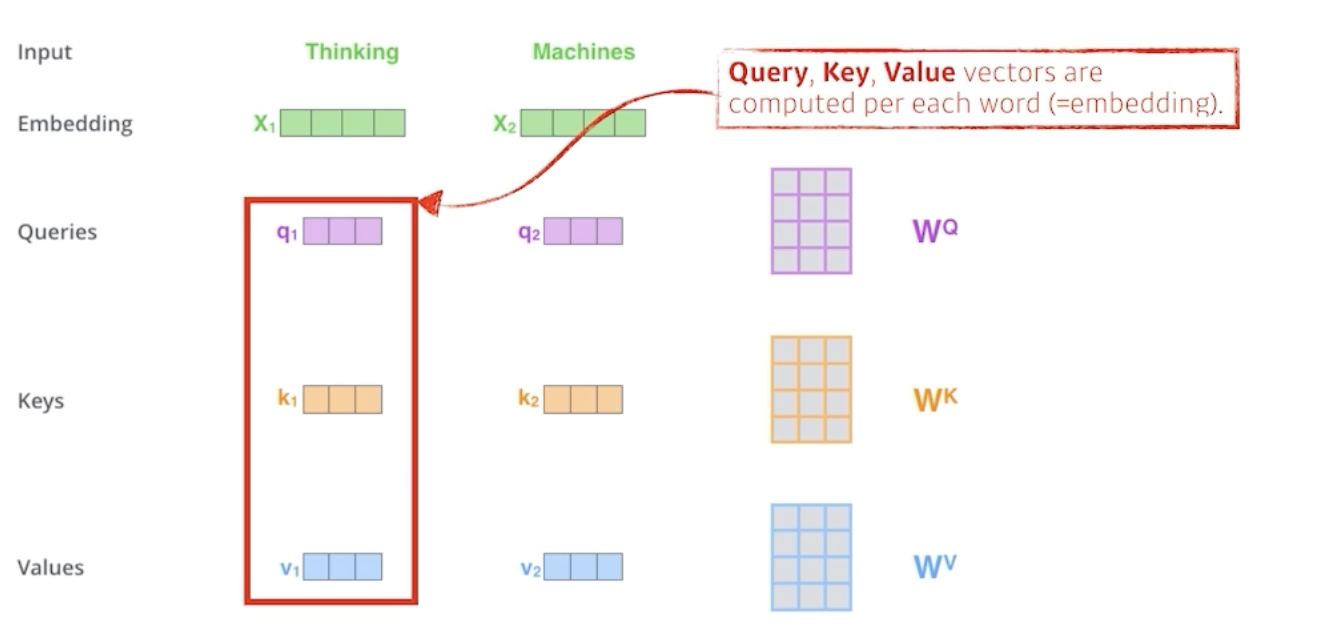
이 3가지 벡터를 통해서 x1이라는 값을 새로운 벡터로 바꾼다.
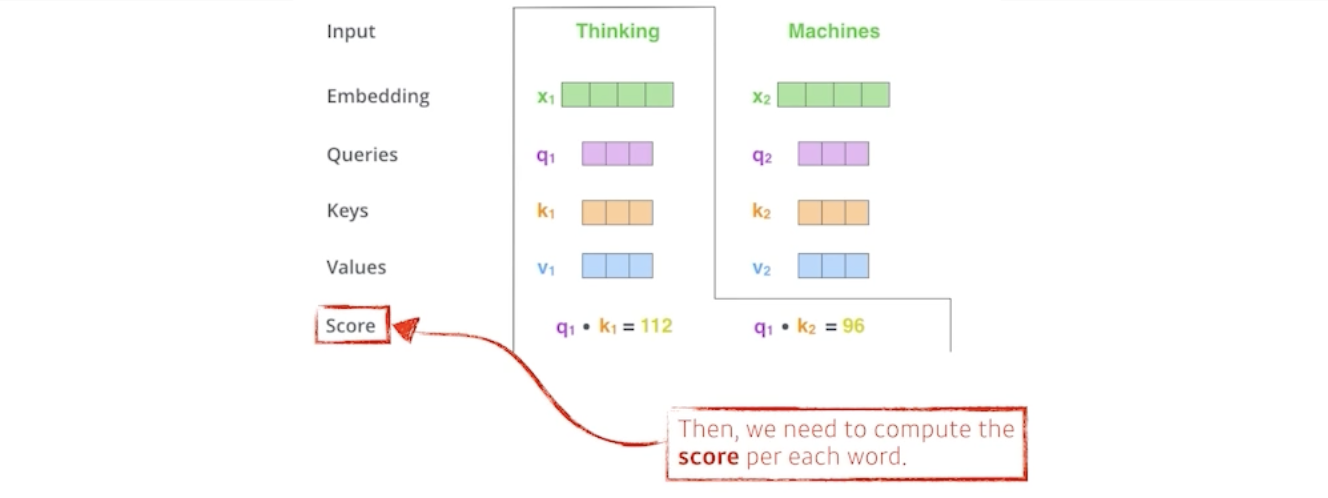
각각의 벡터마다 Q, K, V를 만들었으면, 가장 먼저 해주는 것은 score 벡터를 만드는 것이다.
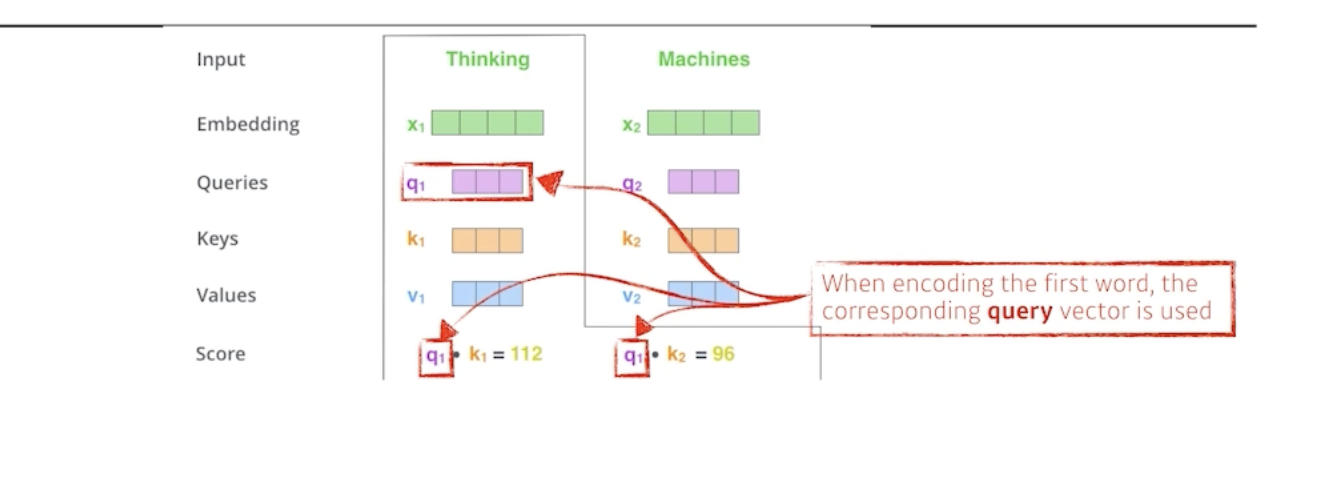
i 번째 단어에 대한 score 벡터를 계산할 땐, 내가 encoding하고자 하는 벡터의 Q와, 나머지 n개의 벡터에 대한 K벡터를 내적한다.
즉, i번째 단어가 나머지 단어들과 얼마나 유사도가 있는지 구하는 것이다.
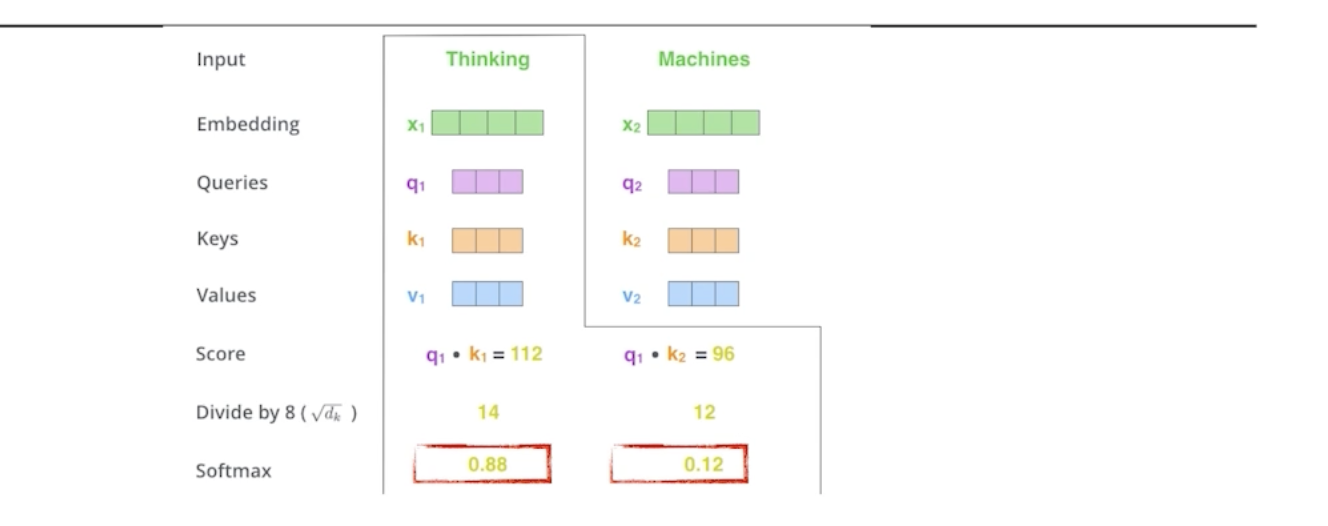
이렇게 score 벡터가 나오면 8로 나눠주면서 normalization 해준다.
여기서 왜 8이 나왔냐면, key vector의 demention에 dependant 하기때문이다. 여기서는 64개의 벡터를 만들었고, 이에 루트를 취해서 8이 나온 것이다. -> score 값이 너무 커지지 않게 만들어주는 것이다.
그리고 나서 정규화된 점수를 확률적으로 표현하기 위해서 softmax를 취해준다.
다음으로 마지막 단계를 거치게 되는데 바로 value와의 weighted sum (외적)이다.
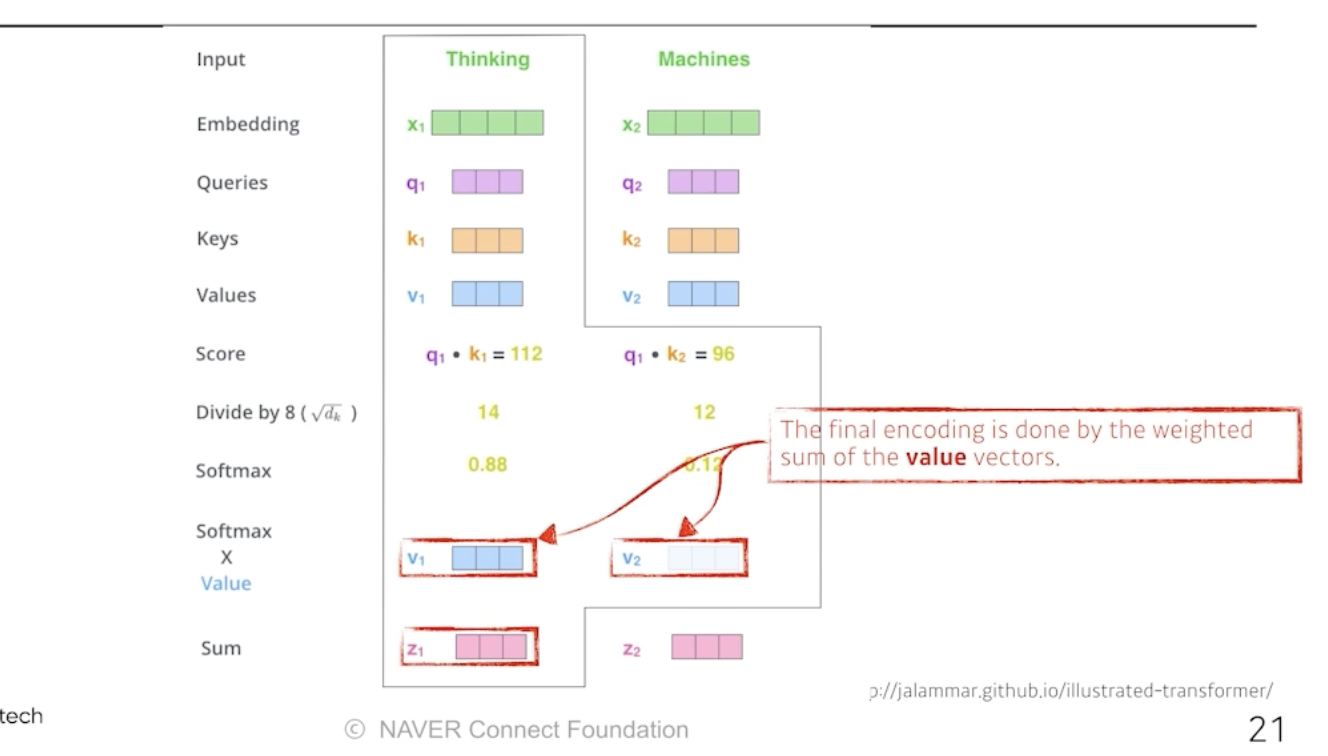
정리하자면,
1. embedding 벡터마다 q,k,v를 만듬
2. q와 k의 내적으로 scalar를 만들고 소프트맥스를 거친다.
3. 최종적으로 사용할 값은 각각의 단어에서 나온 softmax 값과 value 벡터들의 weighted sum이다.
이 루틴을 다 거치면, 하나의 단어에 대한 encoding vector가 나오게 된다.
주의할 점은, q와 k 벡터는 항상 차원이 같아야 한다.
하지만 v는 달라도 된다. 외적을 하기때문이다.
그리고 최종적으로 나오는 thinkning 이라는 벡터의 encoding된 vector는 value 벡터와 차원이 같아질 것이다.
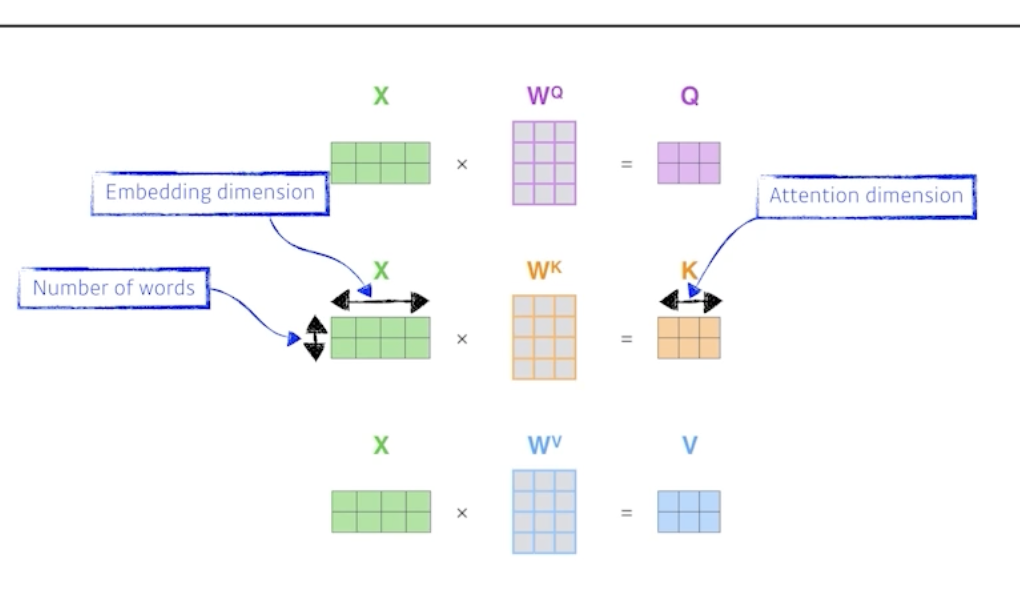
위 그림은 2개의 단어가 들어왔을 때, 각각 matrix곱을 통해 2개의 Q,K,V 벡터를 구하는 과정이다.
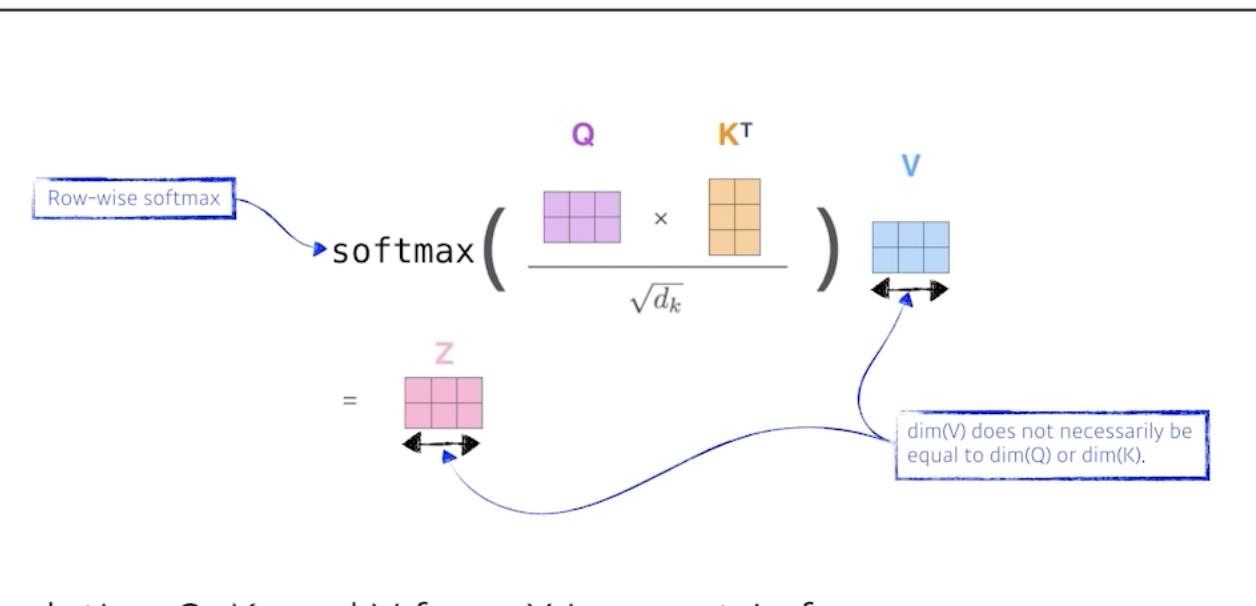
왜 이게 잘될까?
이미지 하나가 주어졌다고 생각해보자. 만약 CNN을 돌리면 input이 fix되어 있는 경우 output도 고정이다.
하지만 Transformer는 잇풋이 고정되어 있더라도, 내가 encoding하려는 입력값과 옆에 있는 다른 입력에 따라서 그 값이 달라진다.
즉, 더 flexible한 모델이므로 훨씬 더 많은 것을 표현할 수 있다.
RNN은 n개 시퀀스가 주어지면, n번 돌리는 것이다.
하지만 transformer는 n개의 단어를 1번에 처리해야기 때문에 n개의 단어가 주어지면 nxn짜리 어떤 attention map을 만들어야 한다. 즉, cost가 n제곱에 비례하기때문에 길이가 길어짐에 따라 처리할 수 있는 한계가 있다.
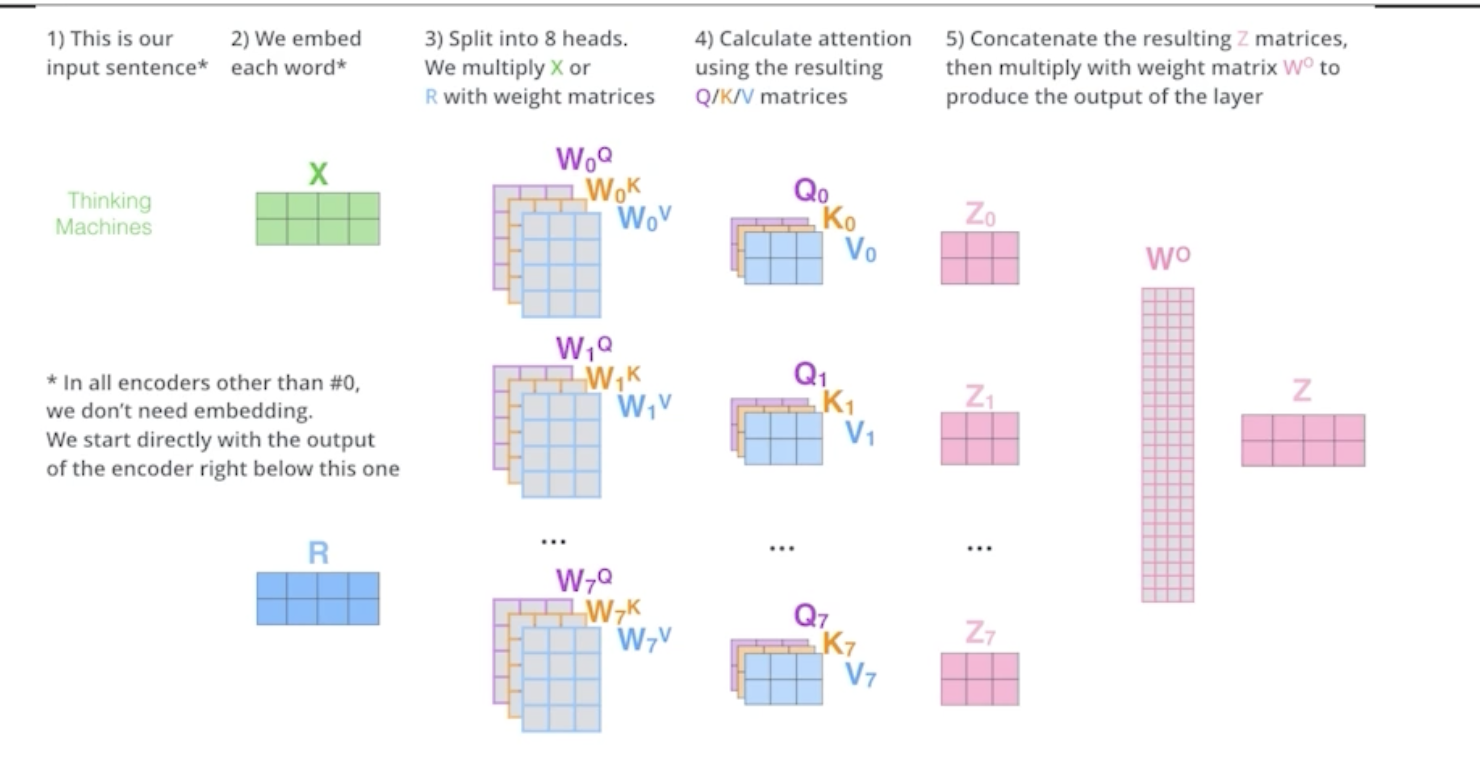
multi-headed attention은,
하나의 embedding 단어에 대해서 q,k,v를 하나씩 만드는 것이 아니라 n개 만드는 것이다.
이로서 n개의 attention을 반복하면 n개의 encoding 벡터가 나오는 것이다.
( ex. 하나의 encoding하려는 벡터가 있으면 8개의 encoding된 벡터가 나오게 된다. )
하지만 여기서, encoder가 다음번으로 넘어가기 위해서는 입력과 출력의 차원을 맞춰줘야 한다. (embedding된 벡터와 encoding을 거쳐 나온 벡터)
따라서 n개의 output을 다시 원래 차원으로 줄여버린다.
추가적으로 positional encoding이 들어간다.
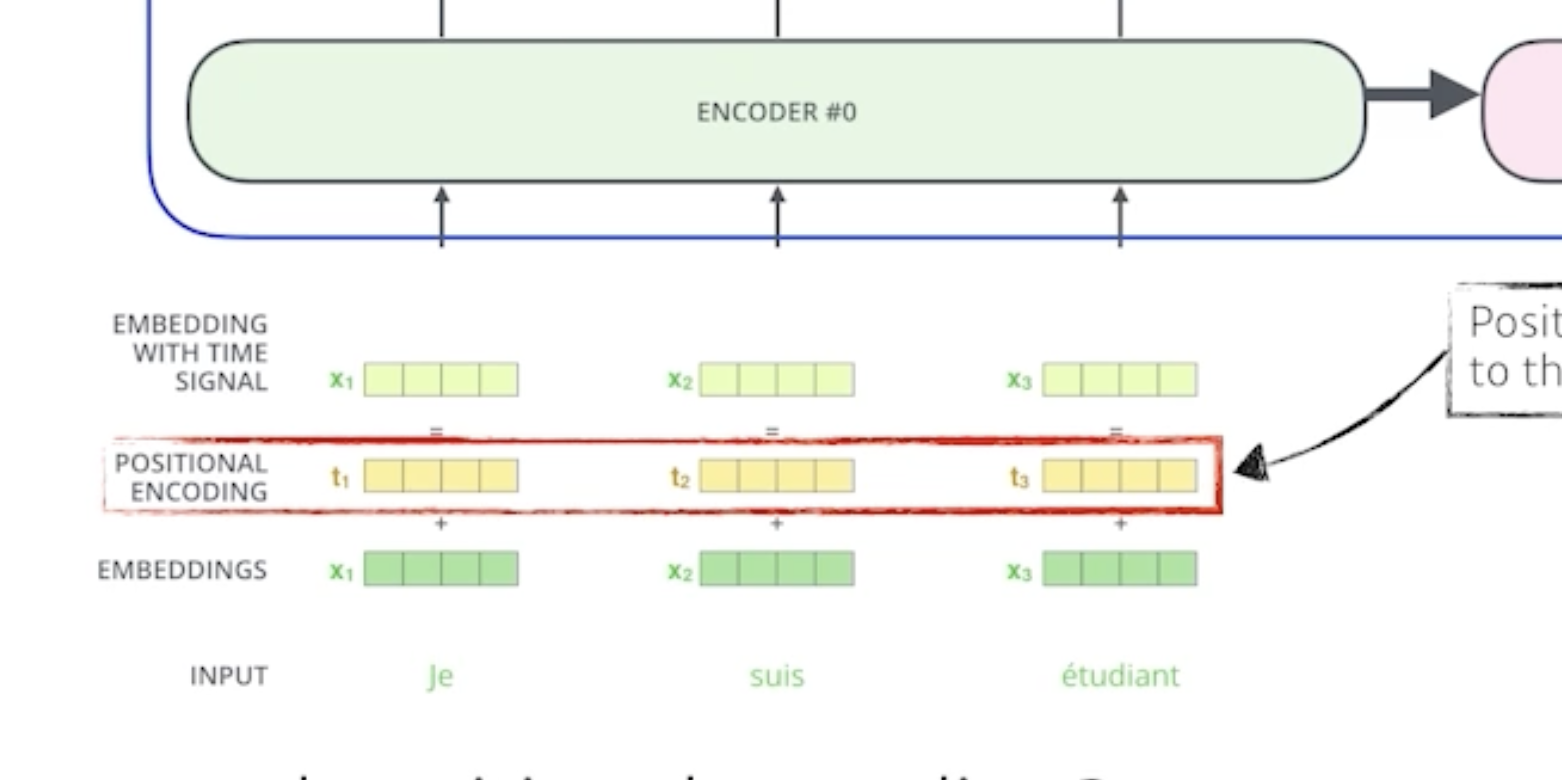
왜 positional encoding이 필요할까?
transformer 구조를 보면, sequential한 정보가 포함될 수가 없다. 즉, 어떤 단어의 순서 order 정보가 들어가지 않는다.
하지만 실제 문장을 만들때는 이 순서가 중요하기때문에 positional encoding으로 이를 가능하게 한다.
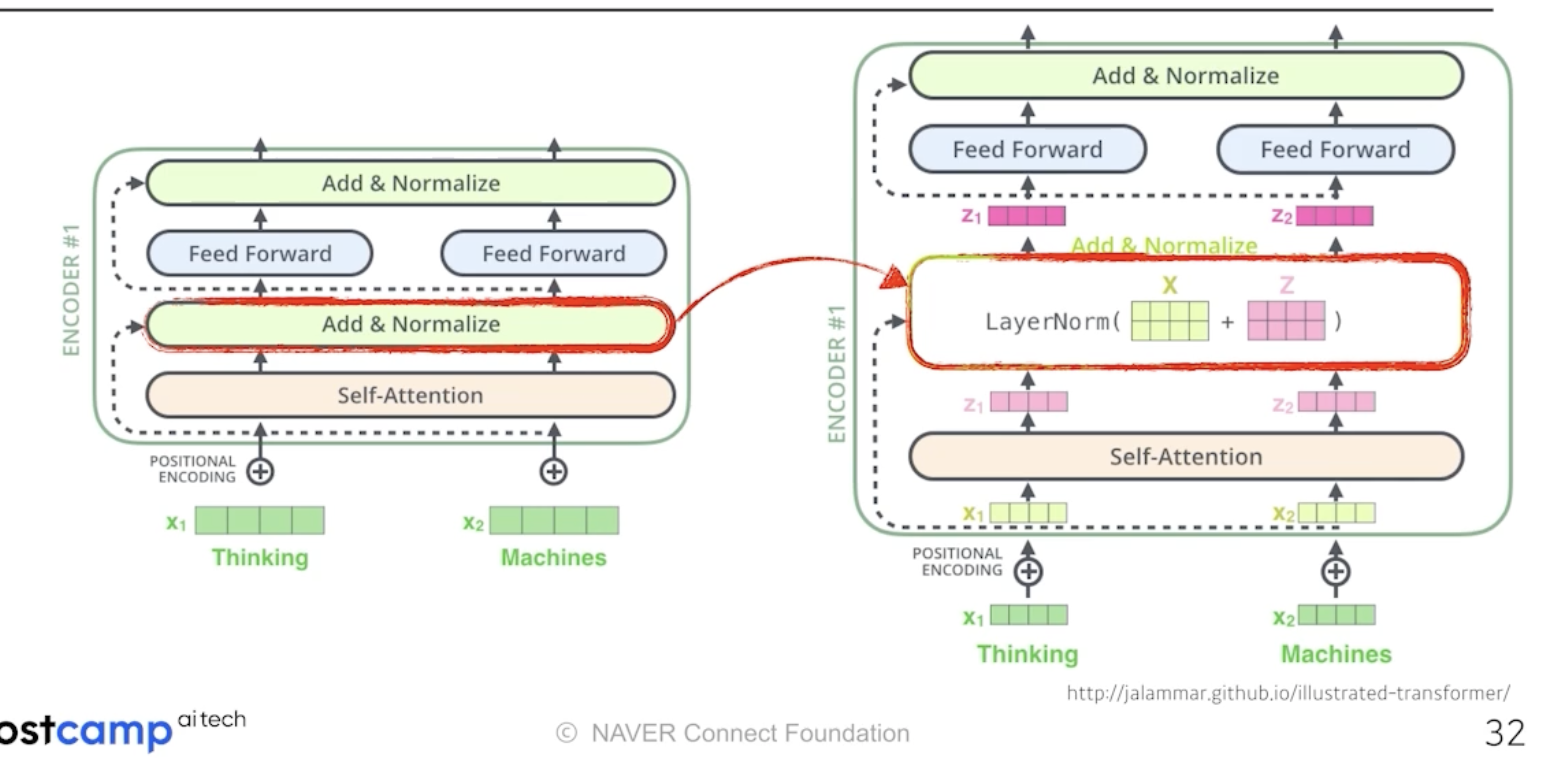
2) encoder와 decoder사이에 어떤 정보가 교환될까?
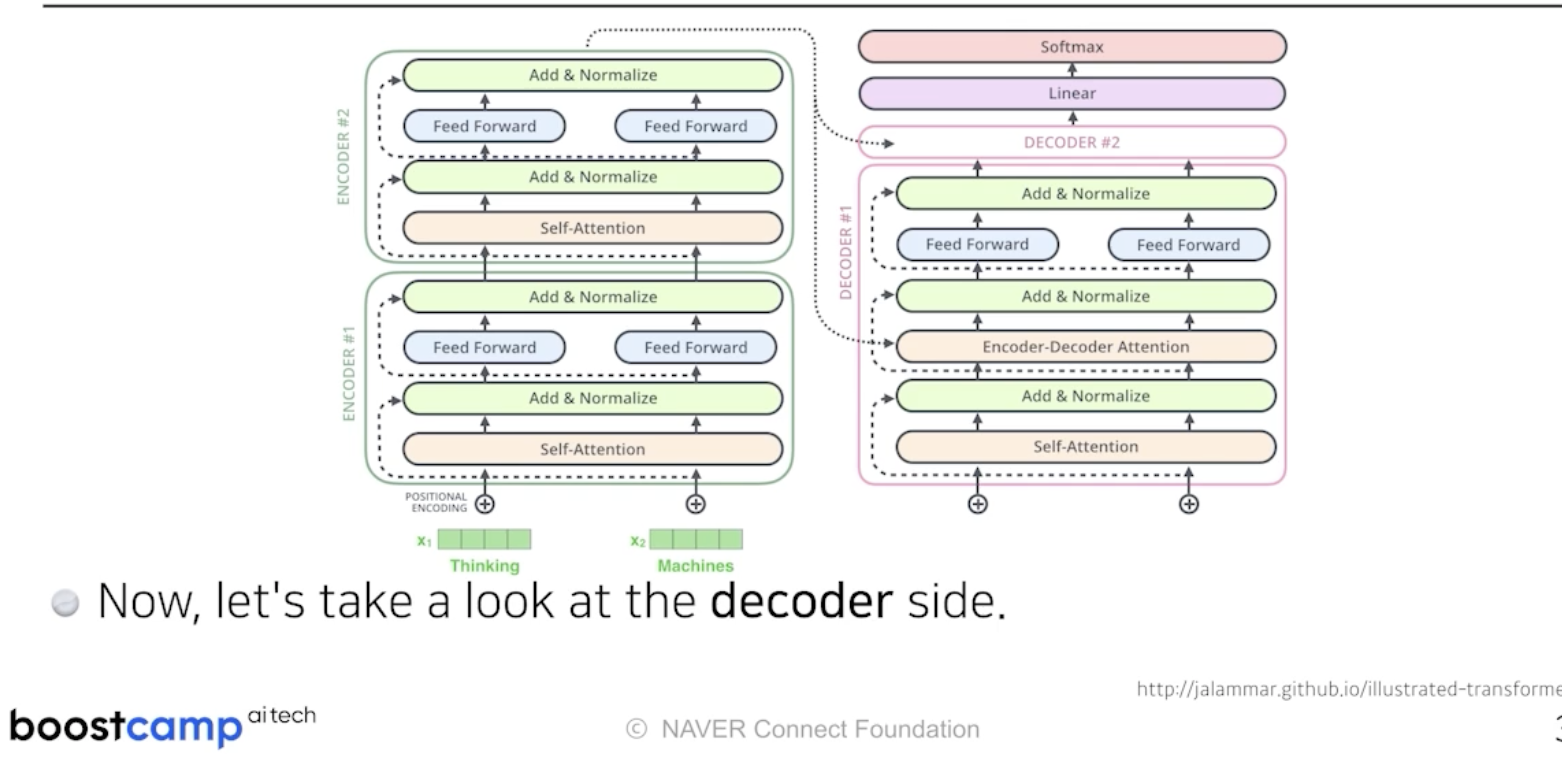
이제 decoder 쪽을 보자.
encoder는 주어진 단어를 표현하는 것이었고, decoder는 이를 갖고 문장을 생성하는 것이다.
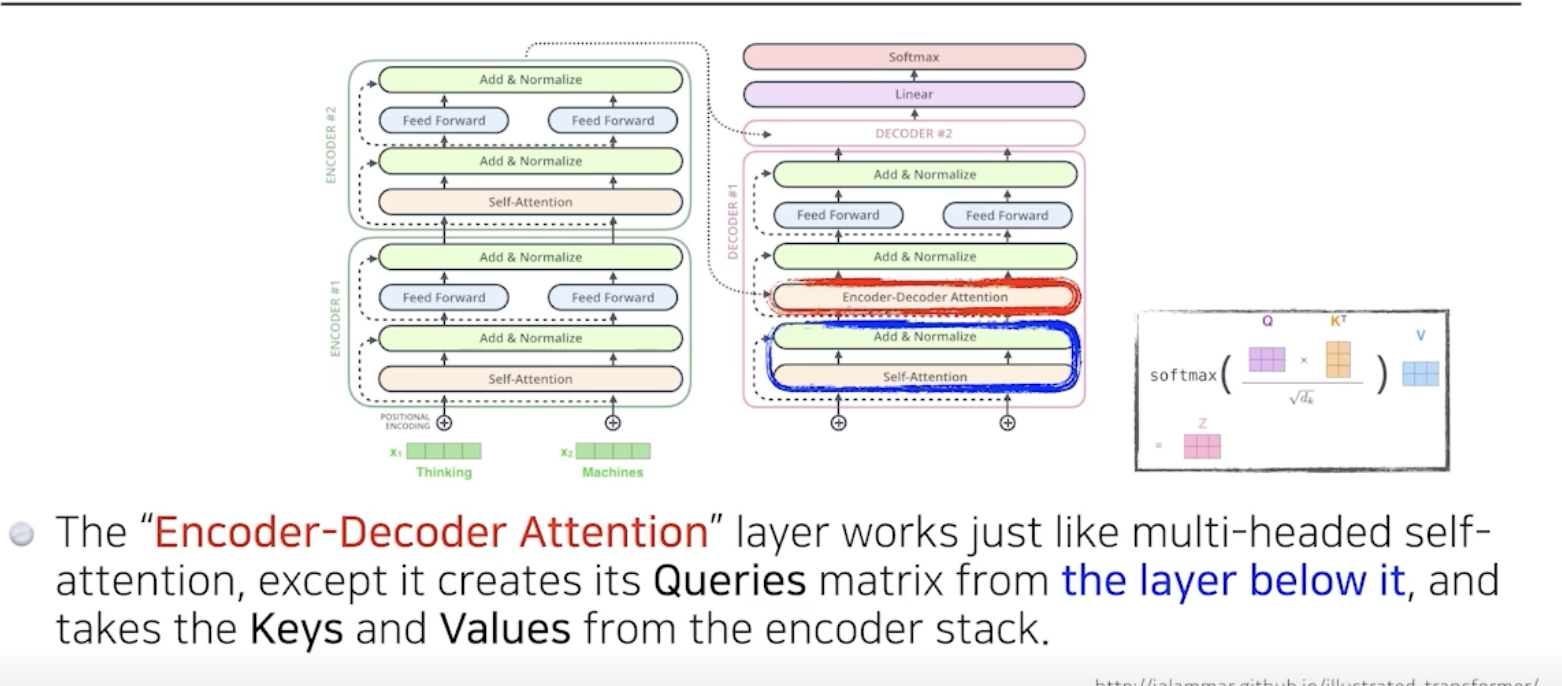
중요한 것은 encoder에서 decoder로 어떤 정보가 전해지느냐 이다.
transformer에서 encoder는 decoder에게 k와 v를 보내는데,
encoder에서는 i번째의 q와 나머지의 k를 곱해서 attention을 만들고 v를 외적하기때문에,
출력하고자 하는 단어에 대해서 attention map을 만들려면, 나머지 단어들의 k와 v가 필요하다.
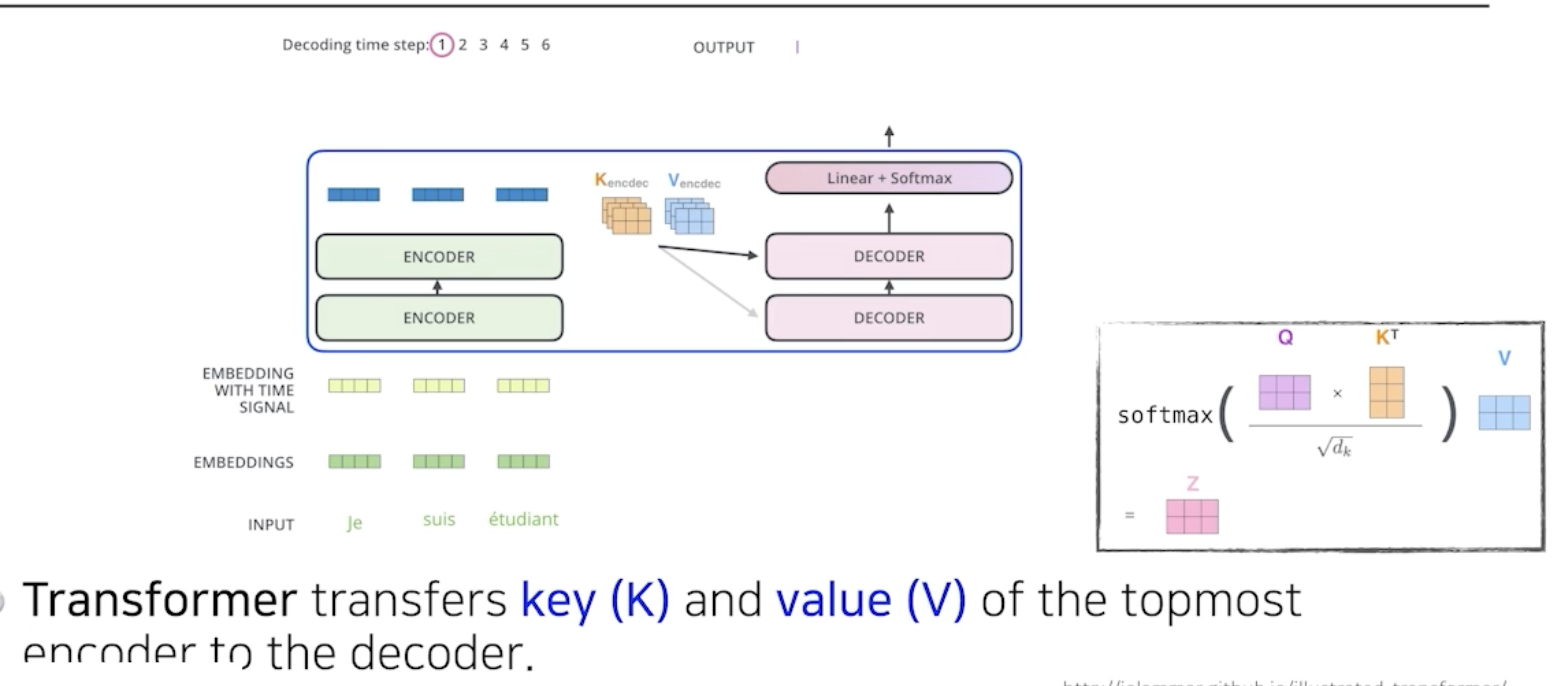
이후 decoder에 들어가는 단어들로 만들어진 q와 encoder로 얻어지는 k와 v를 갖고 최종값이 나오게된다.
최종 출력은 order regressive하게 나온다.
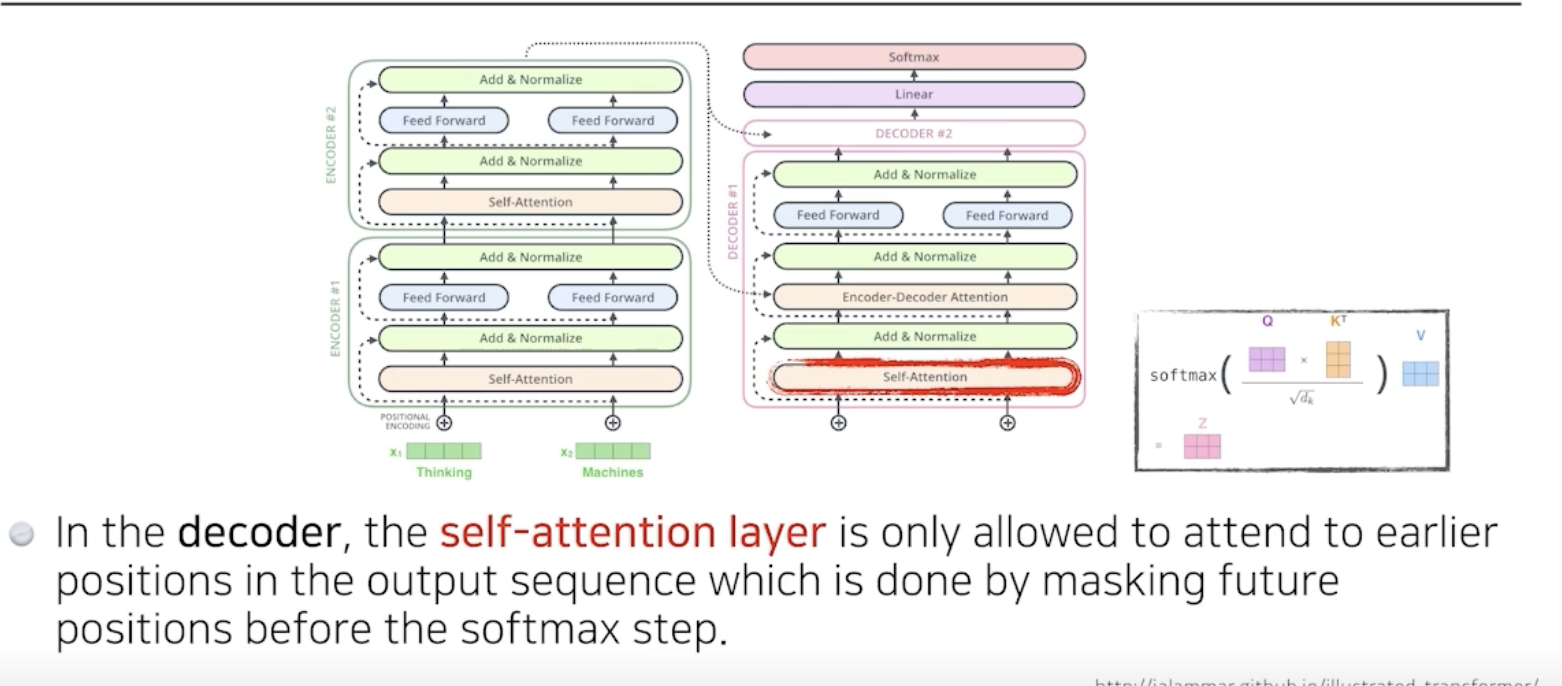
학습 단계에서는 masking을 하게 된다.
이전 단어에만 의존하고, 다음 단어는 가림으로써 미래의 정보는 활용하지 않는 것이다.
Vision Transformer
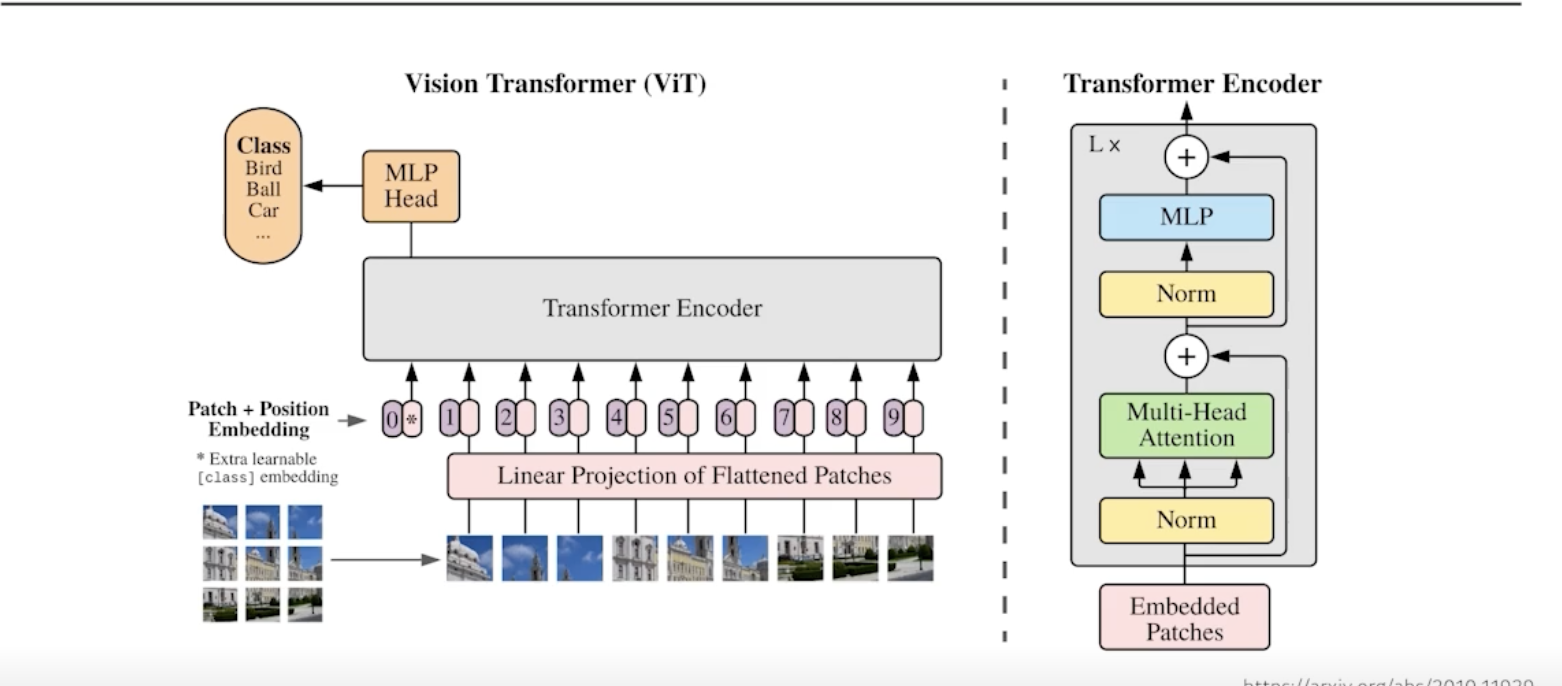
visual transformer 논문을 참고해보면, encoder만 사용한다.
NLP에서는 문장들이 주어지지만, 이미지에서는 한 이미지를 여러 영역으로 나누고, 이를 하나의 입력으로 준다.
+ DALL -E 모델
문장이 주어지면, 문장에 대한 이미지를 만들어준다.
transformer의 decoder만 사용.
'AI Learner > NLP' 카테고리의 다른 글
| [BoostCourse DL] Sequential Models-RNN (0) | 2023.04.19 |
|---|
