
Adore__
[ML] XGBoost model 본문
_INTRO
ECG project를 진행하면서, XGBoost model을 사용하기로 했는데 그 이전에 모델에 대한 사전 지식을 얻고자 공부해보려 한다.
XGBoost 인기는 계속해서 상승하고 있는데, Kaggle에서 매우 큰 성과를 이루면서 주목을 받고 있다.
_What is XGBoost?
XGBoost (Extreme Gradient Boost) 는 Gradient Boosted Decision Tree (GBDT) 계열의 지도학습 알고리즘으로,
다음과 같은 이점을 갖고있다.
- 병렬 처리 (Parallel tree boosting), 자동 가지치기 알고리즘 : 빠른 속도
- 과적합 규제 (Overfitting Regularization) 위한 parameter 추가
- 회귀 (Regression), 분류(Classification), Ranking 문제에 사용
- self Cross validation algorithm , handle missing value
시작하기 이전에 먼저 3가지를 알아야한다.
1. Decision Tree

결정 트리는 판단, 분류를 위한 지식을 트리 형태로 나타낸 것이다.
결정 트리의 내부 노드 (그림에서의 사각형)는 if - then - else 구문으로 나타낼 수 있고 판단에 따라 True, False 간선을 따라가게 된다.
ex.
if Size > 2000 (크기가 2000보다 큰가?)
-- True(크다) --> number of bedroom > 3 ?
-- False(작다)--> number of bedroom > 2 ?
올바른 결정을 내리기 위해서는 그 가능성 (possibility)을 평가해야하는데, decision tree는 최소한의 질문으로 이를 평가하게 된다.
이렇게 입력과 출력 정보가 있는 데이터로부터 결정 트리를 만들면 (지도 학습), 이 결정 트리는 새로운 데이터에 대한 출력값을 예측하는 분류기로 사용된다.
결정트리는 category를 예측하는 분류 문제나, continuous numeric value (상수)를 예측하는 회귀문제에 활용된다.
위 그림의 경우, 결정트리는 bedrooms의 크기와 개수에 따라 house price를 평가하는데 사용된다.
2. Ensemble Learning
Gradient Boosting Decision Trees(GBDT)는 결정트리 앙상블 알고리즘으로, 분류와 회귀를 위한 Random Forest와 유사하다.
Ensemble Learning Algorithms는 더 나은 모델을 만들기 위해 여러가지 머신러닝 알고리즘을 합친다. 최종 예측은 각 알고리즘들의 예측의 평균이나 투표 방식으로 결정하게 된다.
Random forest와 GBDT 모두 여러 Decision Trees으로 이루어져있다는 점에서 같지만, tree들이 만들어지고 combine되는 방법에 있어서 차이점이 있다.
1) Random forest는 결정트리를 만들기 위해 'bagging' 방법을 사용한다. 이때 data set의 random bootstrap 샘플들에서 병렬적으로 생성한다.
모든 결정트리 모델들의 각 예측들의 평균으로 최종 Prediction을 구한다.
2) GBDT는 다른 방법인 'boosting' 방법을 사용한다. boosting 기법에 대한 더 자세한 내용은 다음 포스팅을 참고하기 바란다.
Random forest의 'bagging' 기법은 variance (분산)와 overfitting (과적합)을 최소화 하고,
GBDT의 'boosting'은 bias(편차)와 underfitting (과소적합)을 최소화한다.
3. Gradient Boosting
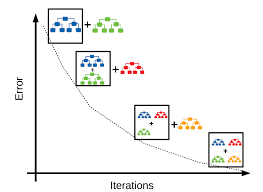
단일 모델은 여러 한계점이 있다. 따라서 'Gradient Boosting'은 더 강한 모델을 만들기 위해 multiple weak model들을 합친다.
Gradient Boosting은 boosting 기법의 확장으로, 이전 모델의 예측 gradient(잔차)를 기반으로 훈련하여 좀 더 보완된 새로운 모델을 만든다.
여기서 핵심은 잔차를 계산하는 방법으로, 모델의 예측과 실제 값 사이의 차이인 residual을 활용한다.
GBDTs는 깊이가 얕은 결정트리들의 ensemble을 반복적으로 훈련한다. 각 iteration에서는 이전 트리의 error residuals (오차)를 이용하여 실수를 살펴보고, 이 실수를 보완한 새로운 트리를 만든다. 최종 예측은 모든 tree의 예측값들을 더해 (weighted sum) 얻는다.
XGBoost은 이러한 gradient boosting의 고급 버전이다. 머신러닝 모델에 있어서 중요한 두 가지 요소인 '성능'과 '속도' 면에 있어서, XGBoost는 일반적인 Gradient Boosting보다 좋은 성능을 내고 빠른 속도를 보인다.
트리들이 직렬로 생성되는 GBDT와 달리, XGBoost는 tree들을 병렬적으로 생성한다. 즉, 훈련 세트를 여러 분할로 나눈다. 그리고 각 분할에서 partial 기울기 값을 스캔한 후 partial 품질을 평가한다.
Why XGBoost ?
XGBoost는 Kaggle에서 매우 큰 성과를 이루어냈으며, 초기에는 Python과 R로 제공되었지만 현재는 Java, Scala, Julia, Perl로도 가능하다.
< Benefits >
- XGBoost open source 구축 활발히 진행 중
- 매우 넓게 응용될 수 있다. ( 회귀, 분류, ranking, 그리고 사용자 정의 예측 문제 등..)
GPUs와 XGBoost
CPU를 이용한 XGBoost는 상당한 시간이 소요된다. 따라서 GPU를 이용하여 대량의 병렬 구조를 구축하는 것이 효과적이다.
Reference : https://www.nvidia.com/en-us/glossary/data-science/xgboost/
'AI Learner > ML' 카테고리의 다른 글
| [Ensemble] Boosting Algorithm (0) | 2023.04.03 |
|---|---|
| [Ensemble] Bagging Algorithm (0) | 2023.04.03 |
| [ML] SVM classifier (0) | 2023.04.03 |

