
Adore__
[ML] SVM classifier 본문
| Date: 0804.2022
ECG project -ing...
_INFO
SVMs, Support Vector Machines 는 머신러닝 알고리즘으로, 분류(classification)와 회귀(regression), 그리고 outlier detection에 사용되는 강력한 알고리즘 중 하나이다. SVM 분류기는 새로운 데이터 points를 주어진 카테고리 중 하나에 지정하기때문에, 비확률적인 2진법 선형 분류기 (non-probabilistic binary linear classifier) 처럼 보이기도 한다.
SVMs는 선형 분류기로 사용될 수 있지만, 추가적으로 kernel을 이용하여 비선형 분류가 가능하다. 즉, inputs 데이터들을 더 고차원적인 feature spaces에 mapping 할 수 있다는 것이다.
* implicit 절대적인 / 함축적인
_Support Vector Machines intuition
먼저, 우리는 SVM 용어(terminology)에 익숙해져야 한다.
'Hyperplane'
hyperplane (초평면)은 여러 labels를 가진 data points를 세트별로 구분하는 decision boundary 이다.
SVM 분류기는 margin이 최대가 되도록 hyperplane으로 데이터들을 분류하는데, 여기서 이 hyperplane은 'maximum margin hyperplane'라고 하며, 이를 설정한 분류기를 'maximum margin classifier'라고 한다.
데이터의 feature이 2개이면 decision boundary가 아래와 같이 선형으로 나타나지만,
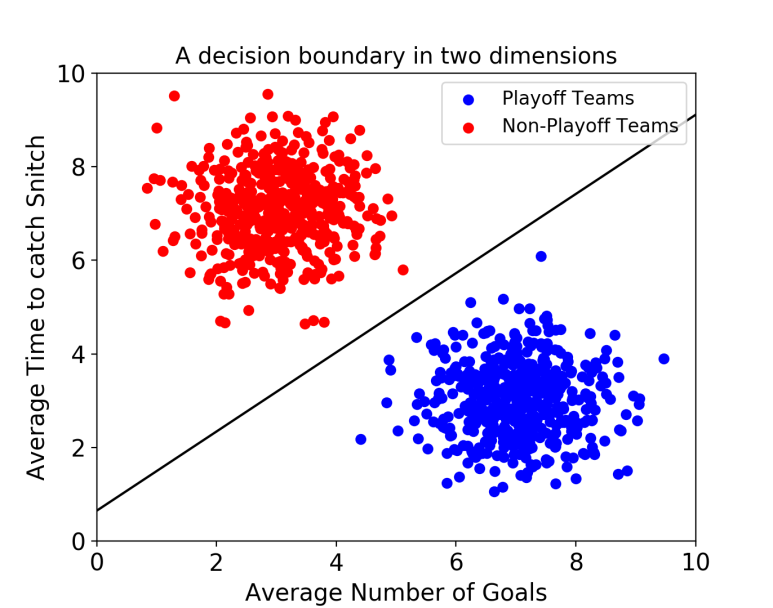
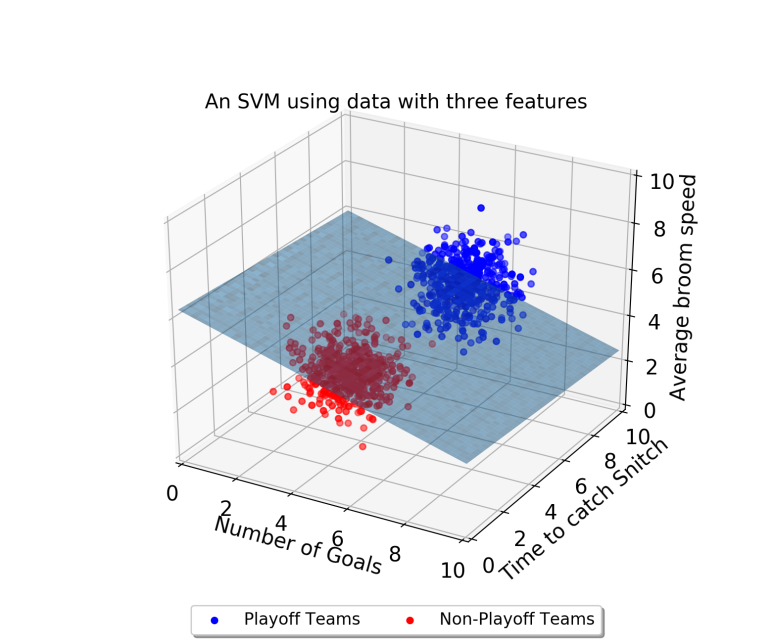
multi labels일 경우 decision boundary를 hyperplane이라고 칭한다.
'Support Vectors'
Support vectors는 hyperplane에 가장 가까운 샘플의 data points을 말한다.
이 points는 margins을 계산해서 위 그림과 같이 2차원의 boundary line이나, 고차원의 hyperplane을 결정한다.
지금까지 Margin이라는 용어가 자주 나왔는데, '그래서 Margin이 뭐야?' 라고 생각하셨다면 설명해드리는게 인Ji상정
'Margin'
Margin은 hyperplane에 가장 가까운 점들(즉, support vectors) 위를 지나가는 두 선 사이의 gap을 말한다.
이는 선에서 support vectors까지 수직으로 그은 거리를 이용하여 계산할 수 있다. SVMs을 사용할 때 우리는 이 gap을 최대화하여 maximum margin을 얻도록해야 한다.
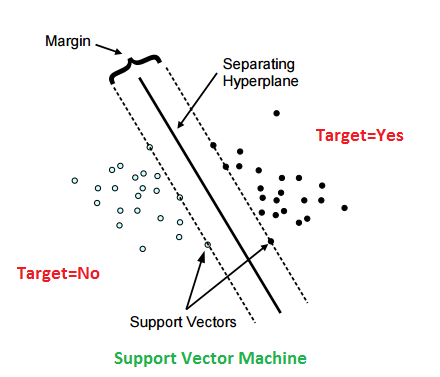
위 그림을 보면 Target = No의 흰색 점 중에 hyperplane에 가장 가까운 점들(support vectors)을 이은 점선1과, Target = Yes의 support vectors를 이은 점선2 간의 수직 거리를 Margin이라고 하는 것이다.
SVM Under the hood
SVMs에서 우리의 주요 목적은 주어진 데이터세트에서 support vectorsrks간의 Margin을 최대화 시키는 hyperplane을 선별하는 것이다. SVM은 이러한 maximum margin hyperplane을 다음과 같은 두 단계로 찾는다.
step 1)
가장 최적의 방법으로 class들을 분류하는 hyperplane을 생성한다.
data를 분류할 수 있는 hyperplane은 여러 개일 수 있는데, 우리는 이 중에서 두 classes 간의 margin, 즉 갭을 가장 크게 갖는 최적의 hyperplane을 찾아야한다.
step 2)
자, 우리는 각 side의 support vectors와 의 거리를 최대화 할 수 있는 hyperplane을 찾았다. 이러한 hyperplane이 존재한다면, 이는 maximum margin hyperplane이고, 이를 결정한 분류기는 maximum margin classifier이다.
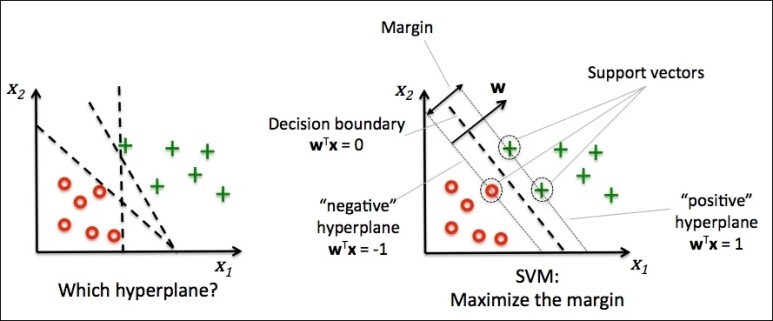
왼쪽의 그림을 보면 저 3개의 점선은 모두 양쪽 support vectors와 너무 가까이 위치해 있다. 이는 최적의 hyperplane이 될 수 없다.
오른쪽 그림과 같이 각 support vectors와 최대의 거리를 가질 수 있게 hyperplane을 설정해야 한다.
결국 이 최적의 hyperplane을 결정하는 것은, 각 classes에서 어떤 support vectors를 얻어내느냐가 될 수 있겠다.
Problem with dispersed datasets
가끔, 샘플 data points이 너무 퍼져있어서 선형 hyperplane으로 분리할 수 없는 경우가 있다.
이러한 상황에서는 SVMs는 kernel trick을 사용하여 input space를 고차원적인 space로 바꾼다 ( ex. 2D -> 3D input space )
처음 hyperplane을 설명했을 때 사용된 그림들을 참고하거나 아래 그림을 참고하자.
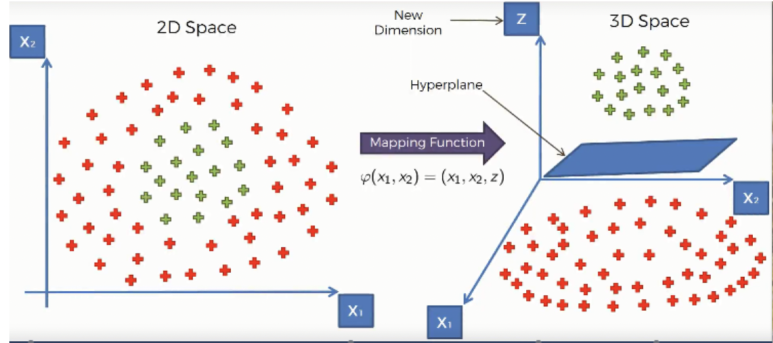
_Kernel Trick
코드를 작성할 때, SVM 알고리즘은 kernel을 이용하여 실행된다. 이는 'kernel trick'이라고 불리는 기술을 사용하는데, 단순하게 'kernel'은 단순하게 데이터를 고차원에 매핑하는 함수를 말한다.\
kernel은 저차원 input data space를 고차원 space로 변환하여 (결국에는 더 많은 차원들을 추가하는 것이다) 비선형 분류 문제를 선형 분류 문제로 바꿀 수 있다. 따라서 kernel trick은 더 정확한 분류기를 가능하게 하므로 비선형 분류 문제 (non-linear seperation problems)에 사용된다.
Kernel 함수는 아래와 같다.
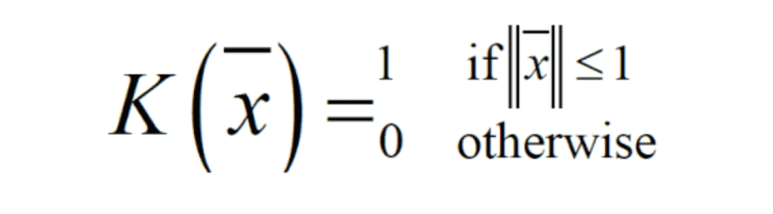
SVMs에서는 4가지 주요 kernels가 있다.
- Linear Kernel
- Polynomial kernel
- Radia Basis Function (RBF) kernel , 가우시안 kernel로 불리기도 한다.
- Sigmoid kernel
하나씩 살펴보자
1. Linear Kernel
linear kernel 함수 : K(xi , xj ) = xiT xj
Linear kernel은 데이터가 선형적으로 분포되어 있을 때 사용한다. 이 말은 데이터가 단순히 하나의 선으로 분류되는 것을 말한다.
가장 많이 사용되는 kernel 중 하나로, 데이터세트의 feature가 매우 많을 때 사용된다. 종종 text 분류 목적으로 사용되기도 한다.
linear kernel을 사용하면 빠르게 training 할 수 있는데, 오직 C regularization parameter 만 최적화하면 되기 떄문이다.
반면에 다른 kernel들을 훈련시킬 경우, γ parameter도 최적화해야 하기때문에 Grid search에 시간이 좀 더 걸린다.
여기서 C parameter는 이상치, 즉 outlier를 얼마나 허용하냐를 결정짓는다.
C 값이 클수록 Hard Margin, C 값이 작을수록 Soft Margin이다.
- Hard Margin : outlier를 허용하지 않고 기준을 까다롭게 한다. 따라서 decision boundary와 support vectors간의 거리가 매우 좁으며, 과적합 문제가 발생할 수 있다.
- Soft Margin : outlier를 어느정도 허용하므로 decision boundery와 support vectors간의 거리가 넓다. 그대신 underfitting 문제가 발생할 수 있다.
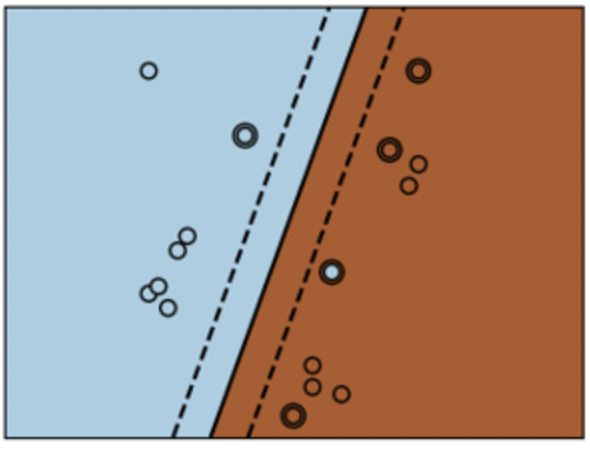
2. Polynomial Kernel
d 차수 다항식에서, polynomial kernel은 다음과 같이 정의된다.
K(xi , xj ) = (γxiT xj + r)d , γ > 0
Polynomial Kernel은 특징 공간(기존 변수들의 다항식으로 만들어짐)의 백터(훈련 샘플)의 유사성을 보여준다.
polynomial kernel은 input 샘플에서 주어진 features만 보는 것이 아니라, input들의 combination도 고려하여 그들의 유사성을 결정한다.
polynomial kernel은 자연어 처리에 유용하다. 가장 많이 사용되는 차수는 d = 2 (quadratic) 인데, 큰 차수는 NLP(자연어처리)에서 과적합문제를 일으킬 수 있기 때문이다.
*polynomial 다항식
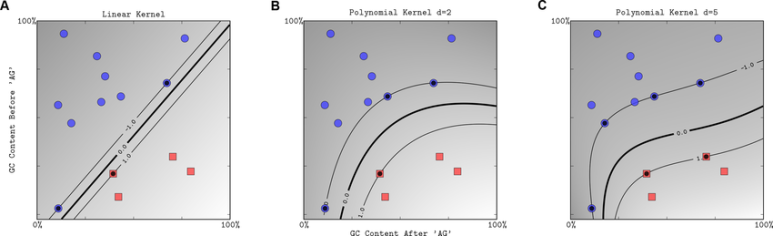
위의 그림에서 d가 커질수록 과적합 되는 경향이 있음을 볼 수 있다.
정리하자면 polynomial kernel은 하나의 선으로 class를 분류할 수 없었던 문제를 아래 그림과 같이 3차원, 4차원 등의 고차원으로 input space를 바꾸면서 hyperplace를 얻어내는 것이다.
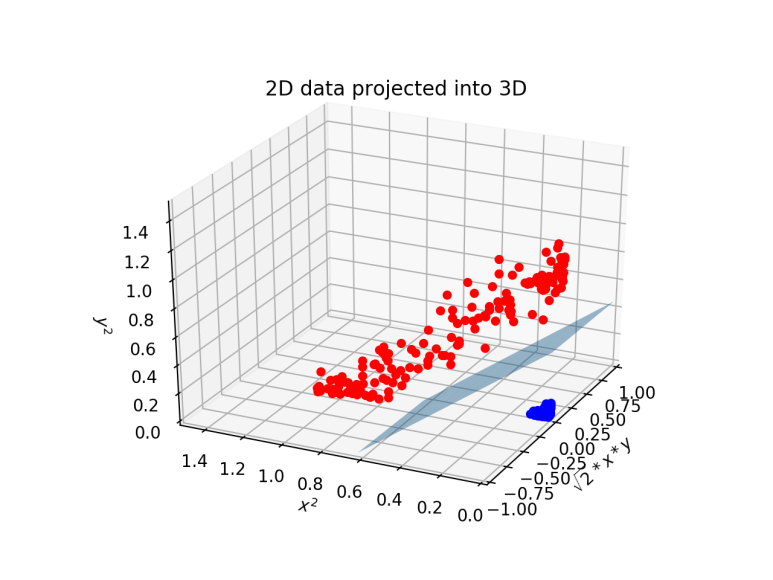
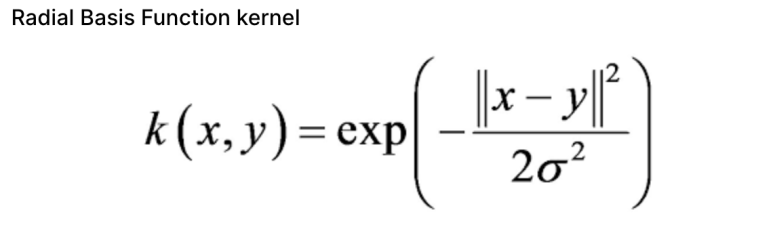
3. Radia Basis Function Kernel
RBF kernel은 일반적인 용도의 kernel이다. 데이터에 대해 사전 지식이 없을 때 사용할 수 있다.
두 샘플 x, y에 대해서 RBF kernel은 다음과 같이 정의된다.
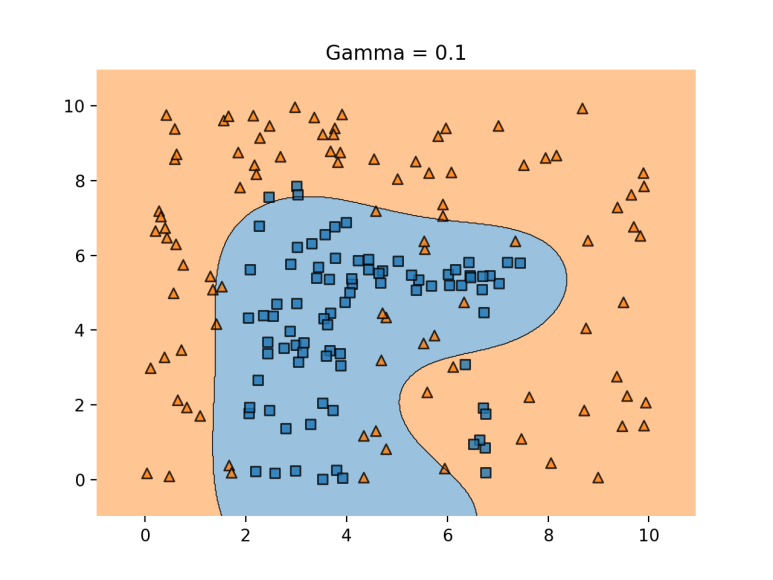
다음 그림은 rbf kernel을 사용했을 때 SVM 분류를 보여준다.
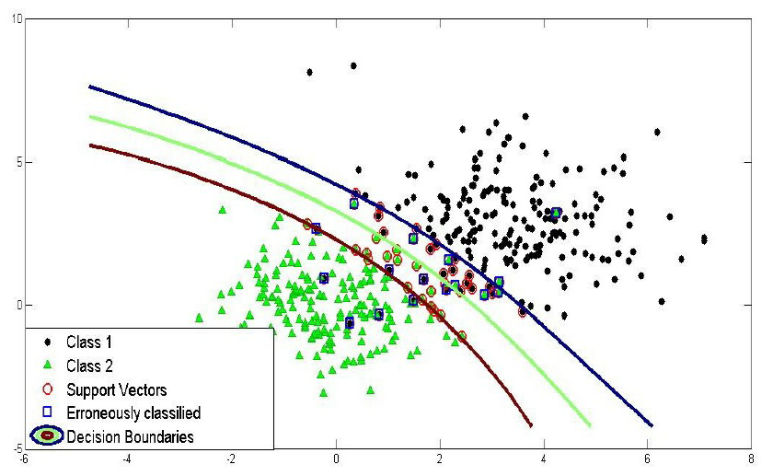
여기서 linear kernel에서 설명했던 C parameter와 마찬가지로 gamma parameter가 등장한다.
gamma는 decision boundary를 얼마나 유연하게 그을 것인지 결정한다.
- gamma 가 클 경우 : 학습 데이터에 많의 의존하여 decision boundary의 유연성이 높아진다 (구불구불). 이는 과적합 문제를 야기할 수 있다.
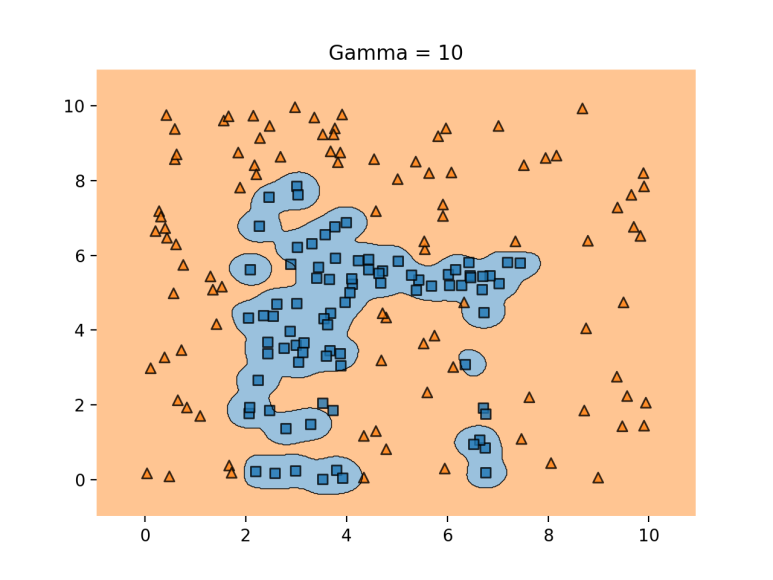
- gamma가 작을 경우 : 학습 데이터 의존성이 떨어져서 decision boundary가 직선에 더 가까워진다. 이는 underfitting이 발생할 수 있다.
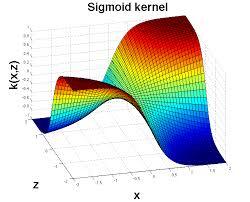
4. Sigmoid Kernel
sigmoid 함수: k (x, y) = tanh(αxTy + c)
Sigmoid kernel은 독자적인 신경망을 가지고 있다. 우리는 이것을 proxy(대리, 대체)처럼 사용할 수 있다 (빌려서 쓴다는 말 같다).
sigmoid kernel을 시각화하면 다음과 같다.
우선 여기까지 SVM의 기본 이론을 살펴 보았다.
Scikit-Learn Libraries를 사용하여 코드를 짜는 것은 다음 시간에 도전해보겠다.
_REF
- https://www.kaggle.com/code/prashant111/svm-classifier-tutorial/notebook
'AI Learner > ML' 카테고리의 다른 글
| [Ensemble] Boosting Algorithm (0) | 2023.04.03 |
|---|---|
| [Ensemble] Bagging Algorithm (0) | 2023.04.03 |
| [ML] XGBoost model (0) | 2023.04.03 |

