
Adore__
[CNN] VGG16 model 본문
_INTRO
ECG project에서 여러 개의 DL model을 사용하고 있는데, 생소한 모델이 많아서 하나씩 정리해 보려고 한다.
그 중 VGG model 과 구현 방법에 대해서 알아보자.
VGG는 VGGNet으로도 알려져 있는데, 이는 CNN구조를 가진 네트워크로, CNNs의 깊이를 늘려서 모델 성능을 향상시키 위해 개발되었다.
_VGG
VGG는 Visul Geometry Group의 약자로, 다중 layers가 있는 deep CNN 구조이다. 여기서 deep은 layer의 수를 말하며, layer가 16개인 VGG-16, 19개인 VGG-19가 있다.
* stand for: (숙어) ~을 나타내다, 의미하다, 상징하다.

VGG는 획기적인 객체 인식 모델의 기초이다. 심층 신경망으로 개발된 VGGNet은 ImageNet 이외에도 많은 작업과 데이터 세트에 대한 baseline(기준선)도 뛰어 넘는다. 이는 현재 가장 많이 사용되는 이미지 인식 방법 중 하나이다.
* ground-breaking: 획기적인
* surpass : 능가하다
* ImageNet: visual 객체 인식 software 연구에 사용하기 위해 만들어진 대규모 visual database이다(1000개 class). MNIST(10개 class)와 CIFAR-10(10개 class) 더불어 model 학습/검증/평가에 자주 사용되는 데이터셋이다.
* Image recognition: AI 응용 기법 중 하나로, 이미지 안에서 특정 사물을 식별하고 어떤 category에 속하는지 인식하는 작업. (나중에 따로 정리해야겠다)
_VGG16
16개 layers를 지원하는 VGG model (VGGNet)인 VGG16은 Oxford대학의 A.Zisserman과 K.Simonyan이 제시한 CNN model이다.
이들은 연구 논문 “Very Deep Convolutional Networks for Large-Scale Image Recognition.” 에 VGG16 모델을 발표했으며, 네트워크의 깊이를 깊게 만드는 것이 성능에 어떠한 영향을 미치는지 확인한다.
* depth: 연속적인 convolution layer의 갯수
VGG16은 ImageNet에 대한 정확도 중 top 5에 드는 약 92.7%의 정확도를 보여줬다 (ImageNet은 약 1000개 class에 속하는 1400만개 이상의 이미지로 구성된 데이터 세트이다).
더군다나 이 모델은 2014년도 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 준우승을 했다. size가 큰 kernal을 사용하는 대신, 여러개의 3x3 kernal을 사용하기 때문에 AlexNet에 비해 상당히 개선되어 있다. 이 모델은 몇 주 동안 Nvidia Titan Black GPU를 사용하여 train되었다.
정리하자면, VGGNet-16은 16개의 layer를 가지며 이미지를 키보드, 동물, 연필 등을 포함한 1000개의 class로 분류할 수 있다. 모델의 이미지 입력 크기는 224x224이다.
_VGG ARCHITECTURE
VGGNets은 CNN 특징 중 가장 필수적인 부분에 기반하였다. 다음은 CNN이 어떻게 작동하는지 기본적인 concept을 보여주는 사진이다.
Input으로 이미지를 넣어주면, CNN network안의 여러 layers를 통과하여 5가지 class에 대한 예측점수(가능성)을 output으로 출력한다.
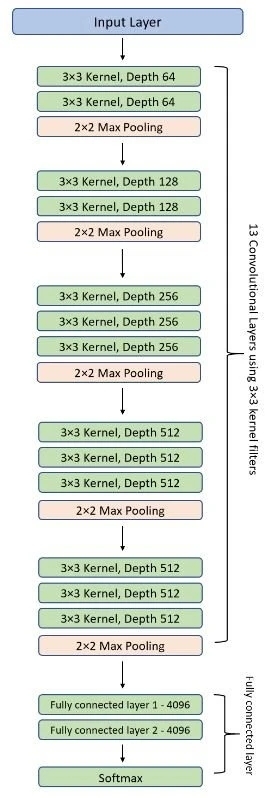
VGG network는 아주 작은 convolutional filters로 이루어져 있는데, VGG-16은 13개의 convolutional layers와 3개의 connected layers로 구성되어 있다.
VGG의 구조에 대해 간단하게 살펴보면,
1) Input
VGGNet은 224x224 크기의 이미지를 input으로 받는다. ImgaeNet competition에서, 모델 개발자는 이미지의 입력 사이즈를 일관되게 유지하기 위해 각 이미지의 중앙 224x224 patch(조각, 파편)를 잘라냈다.
* 224 x 224 matrix: 이미지는 픽셀로 구성되어 있다. 그리고 각 픽셀마다 0또는 1의 값을 부여하여 matrix를 만들 수 있다. 이를 input으로 집어 넣는 것이다.
= 224 x 224 단위의 픽셀로 구성되어 있는 2차원의 Input image를 224x224 matrix로 표현하여 이를 입력값으로 집어 넣는다.
2) Convolutional Layers
VGG의 convolution layer는 kernel size를 가장 작은 사이즈, 3x3 filter(위 아래, 왼쪽 오른쪽을 캡쳐할 때 가능한 가장 작은 크기)로 하며 입력을 선형으로 변환시키는 padding size를 1x1로 설정한다.
* kernel : filter와 같은 의미이다. 224 x 224 matrix의 모든 영역에 같은 필터를 반복 적용(흝기)하여 연산처리를 한다. (matrix 간의 inner product; 같은 크기의 두 matrix에서 같은 위치에 있는 숫자를 곱해 모두 더해 줌)
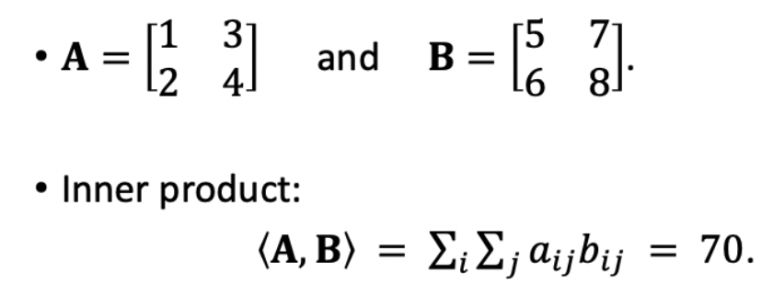
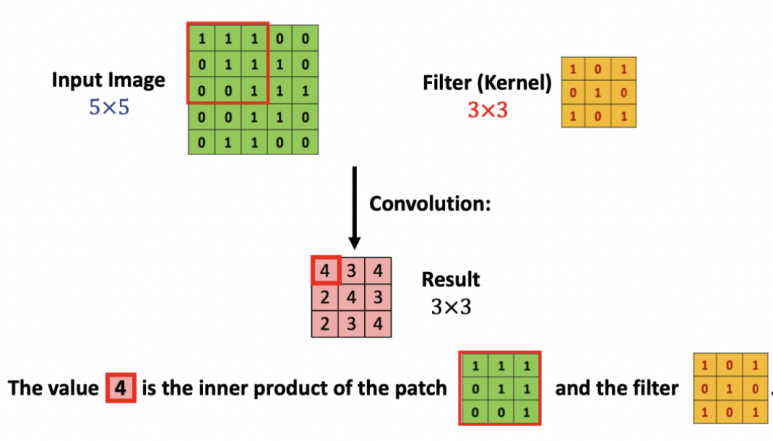
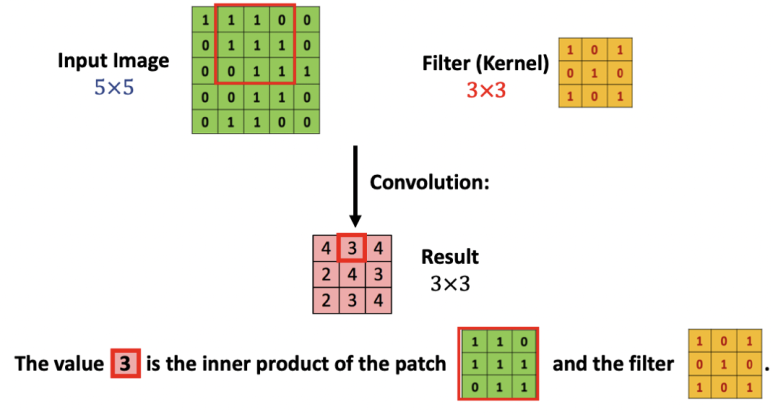
* zero padding: 앞의 convolution 처리를 보면 기존 input data에 비해 convolution 후의 size가 작아지면서 손실되는 부분이 발생하는 것을 볼 수 있다. 이러한 점을 해결하기 위해 사용되는 방법으로, 0으로 구성된 테두리를 이미지 가장자리에 감싸서 추가하는 방식이다.
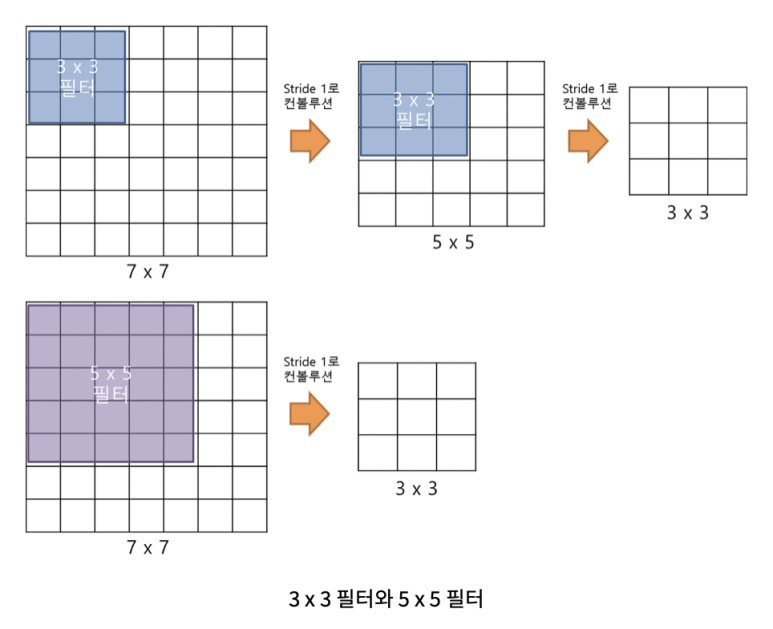
ex_ 5x5 size의 input이 7x7이 되고, 이 상태에서 3x3 filter(kernel)을 적용하면 초기 입력값의 크기와 결과값의 크기가 같아진다. 즉, 손실이 사라진다.
- VGGNet에서 3x3 filter를 사용한 이유
: 3x3 필터 2개 는 총 18개의 가중치를 갖고 5x5 필터는 25개의 가중치를 갖는데, 가중치가 적다는 것은 훈련시켜야할 대상의 갯수가 적어진다는 뜻이다. 이는 학습 속도에 영향을 미칠 수 있다.
: 앞에서 말했듯이, VGGNet은 네트워크의 깊이를 깊게 만드는 것이 성능에 어떠한 영향을 미치는지 연구하기 위해서 설계됐기 때문에 convolutional kernel 사이즈를 한 사이즈로 정하고 convolution의 개수를 늘리는 방식으로 테스트를 진행한다
이 다음에는 ReLU가 나온다. ReLU는 Rectified Linear Unit 활성화 함수로, input이 양수일 경우 출력하고, 아닐 경우 0으로 출력하는 불연속적인 선형 함수이다. convolution 이후에도 공간 해상도를 유지하기 위해 1 convolution stride (입력 행렬,matrix에 대한 픽셀 이동 수)는 1 픽셀로 고정된다.
* stride : 보폭, 진행 . 여기서는 필터를 한 번 이동할 때 얼마만큼(몇개의 픽셀만큼) 움직여 주는가.
3) Hidden Layers:
VGG의 모든 hidden layers는 ReLU를 사용한다. VGG는 보통 LRN(Local Response Normalization)을 활용하지 않는데, 메모리 사용량과 훈련 시간을 증가시킬 뿐만 아니라 전반적인 정확도를 향상시키지 않기 때문이다.
4) Fully-Connected Layers:
VGGNet은 3개의 fully connected layer를 가지고 있다.
3개 중에 처음 두개는 각각 4096 채널을 가지고 있고, 3번째 layer에는 1000개의 채널(class당 1개씩인데 1000개의 class를 가지고 있으므로 1000개 channels)을 가지고 있다.
* crop out: 잘라내다.
* leverage : 행동력, 효력, 영향력 / 활용하다.
* rectify : 조정하다
* piecewise : 불연속으로 (adv)
_VGG16 ARCHITECTURE
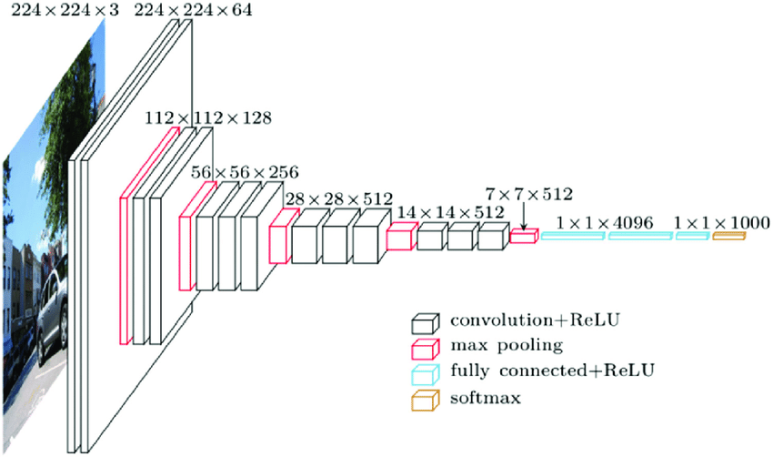
앞에서 여러번 말했듯이, VGG 16의 16은 16개 layers (13개의 convolutional layers와 3개의 connected layers) 의 심층 신경망이라는 뜻이다.
VGG16이 상당히 광범위한 네트워크이며 총 약 1억 3800만 개의 parameters를 가지고 있다. 현대 표준에 따라서도 이는 거대한 네트워크이다.
하지만 동시에 VGGNet 16의 단순한 구조는 큰 장점으로 다가온다. 그 구조만 봐도 상당히 uniform(획일적인)이라고 할 수 있다.
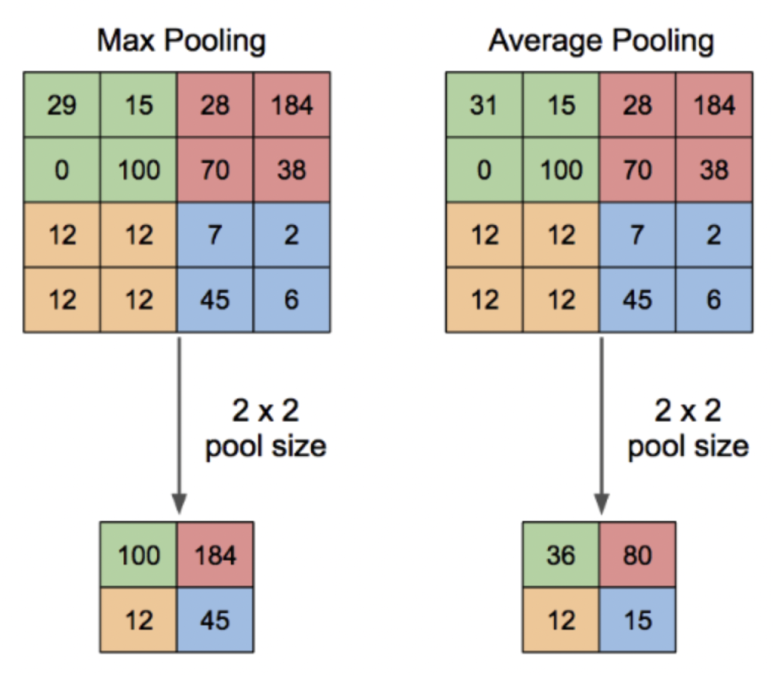
높이와 너비를 줄이는 pooling layer (max pooling: 여기서 kernel size는 2x2, stride 2로 이미지를 절반으로 resize한다) 앞에는 몇 개의 convolution layers가 있다. 우리가 사용할 수 있는 필터의 수를 보면, 약 64개 filters를 사용할 수 있고 2배로 늘려서 128개, 그리고 256개로 늘린다. 마지막 layer에서는 512개의 filter를 사용할 수 있다.
- Input image
: 224x224x3 이미지를 입력으로 받는다.
- 1st Layer (conv-64)
: 64개의 3x3x3 filter kernel로 입력 이미지를 convolution 한다. stride(보폭)과 Zero Padding 모두 1로 설정하면 Output으로 224 x 224 x 64 Feature Map을 얻는다 (zero padding을 했으므로 입력값과 결과값의 size가 224로 같음)
이후 도출해낸 결과값에 Activation function(ReLU)를 적용하면 선형함수인 convolution에 비선형이 추가되고, 첫번째 Conv Layer가 완성된다.
( 한 Conv Layer = Convolution 처리 + ReLU )
- 2nd Layer (conv-64)
: 64개의 3x3x64 kernel로 이전 단계의 Feature Map을 Convolution해준다. 앞과 마찬가지로 Output으로 224x224x64 Feature Map을 얻고, 활성화 함수 ReLU함수를 사용한다.
그리고 2x2 Max Pooling을 stride 2로 설정하면, 112 x 112 x 64 Feature Map이 나온다.
* pooling: convolution 과정을 통해 수많은 결과값(feature map)이 도출되어버리기 때문에 correlation이 낮은 부분을 제거하여 feature map의 dimentionality를 축소(크기를 줄인다)한다.
- 3rd Layer (conv-128)
: 128개의 3 x 3 x 64 kernel로 이전 Feature Map을 Convolution해주면 112 x 112 x 128 Feature Map을 얻고 ReLU함수를 사용한다.
....
이러한 방법으로 13개의 Convolution Layer를 거치게 된다.
- Flatten
13번째까지 픽셀은 7로 줄어들어 7x7x512 Feature Map을 얻었고, 이를 Flatten 해주어 7x7x512 = 25088차원의 벡터로 만들어준다.
- 14th Layer (Fully connected layer)
25088차원의 벡터에 Dropout을 적용하여 4096개의 뉴런과 Fully Connection을 해주고, 이후 ReLU 함수로 활성화한다.
- 15th Layer (FC)
이전 단계의 4096개 뉴런에 Dropout을 적용하여 다른 4096개 뉴런과 fully connection 해준 후 ReLU 함수로 활성화 한다.
- 16th Layer (FC)
이전 단계의 4096개 뉴런에 다른 1000개 뉴런과 fully connection 해준 후 ReLU 함수로 활성화 한다.
이후 1000개 뉴런 출력값에 Softmax 함수를 적용하여 1000개 class에 각각 속할 확률 값을 출력한다.
이로서 3개의 Fully connected Layer를 거쳐 Softmax까지 마무리 되면 최종적으로 각 class별 probability가 나온다.
연구 결과를 보면 Network 깊이가 깊어질수록 오류는 줄어들지만, 16 layer과 19 layer를 비교했을 때는 오류가 비슷하거나 오히려 더 나빠지는 경향을 보였다.
_COMPLEXITY AND CHALLENGES
필터의 수는 convolution layer의 모든 stack을 하나하나 지나갈 때마다 두배가 된다. 이는 VGG16 network의 구조를 디자인할 때 사용되는 기본적인 방법인데, 이 네트워크의 치명적인 단점이 네트워크가 너무 거대해서 parameters를 train하는데 시간이 오래 걸린다는 것이다.
fully connected layers의 깊이와 수 때문에 VGG16 model은 533MB를 넘는다. 이는 VGG network 실행하는데 많은 시간을 소요하게 만든다.
VGG16은 여러 이미지 분류 문제에 사용되지만, 이보다 작은 network 구조인 GoogLeNet, SqueezeNet이 종종 선호되기도 한다.
어쨌든, VGGNet은 좋은 building block이다.
* in any case = anyhow 하여튼
_IMPLEMENTATION IN PYTHON
이건 내가 이 포스팅을 끝내고 다음주까지 교수님께 제출해야 할 과제...ㅎ
_REFERENCE
VGG-What you need to know: https://viso.ai/deep-learning/vgg-very-deep-convolutional-networks/
VGG16 Implementation in Keras: https://towardsdatascience.com/step-by-step-vgg16-implementation-in-keras-for-beginners-a833c686ae6c
'AI Learner > DL' 카테고리의 다른 글
| [BoostCourse DL] 3.2 Optimization_Regularization (0) | 2023.04.06 |
|---|---|
| [BootCourse DL] 3. Optimization_Gradient Descent Methods (0) | 2023.04.06 |
| [BoostCourse DL] 2. Neural Network, MLP (0) | 2023.04.03 |
| [BoostCourse DL] 1. Start (0) | 2023.04.03 |
| [Keras] VGG16 implementation (0) | 2023.04.03 |


