
Adore__
[Keras] VGG16 implementation 본문
_INTRO
이전 포스팅에서는 VGG16의 개념에 대해 다뤘다면, 이번에는 직접 python으로 구현하기 위해 Keras를 사용하는 방법을 알아보겠다.
_DATASET PREPARATION
Dogs vs Cats Dataset : https://www.kaggle.com/c/dogs-vs-cats/data
위 링크로 들어가서 데이터셋을 다운로드 받자 (나는 project에 맞춰 ECG datasets를 사용했다)
다운로드를 완료했으면 다음 libaries를 import해준다.

- Sequential : Sequential model을 만들기 위해 사용한다. Sequential model은 모델의 모든 layers가 순차적으로 나열되었다는 뜻이다.
- ImageDataGenerator : 이 library는 data를 label과 함께 model로 쉽게 import하기 위해 사용된다. 이는 rescale, rotate, zoom, flip 등 많은 기능이 있어서 매우 유용하다. 가장 유용한 점은 디스크에 저장된 데이터에 영향을 미치지 않는다는 것이다. 이 class는 데이터를 모델에 전달하는 동안, 이동 중에 데이터를 변경한다. 하지만 나는 이미지 data가 아니라 X, y (label)이 나뉘어져 있는 데이터인데 다른 방법을 사용해야 할까? train에만 oversampling을 하고 model을 돌려야 하는데.. 그러면 oversampling을 한 데이터를 다시 합쳐서 directory로 저장해야 하나? 아무리 생각해도 이 방법은 번거로운 것 같다.
train과 test data에 대한 ImageDataGenerator 객체(trdata, tsdata)를 생성하고 아까 다운받은 파일 중 "data" directory folder를 trdata에, "train" directory folder를 tsdata에 넘겨준다.

- flow_from_directory(directory = "파일경로", target_size = 사이즈)
데이터의 폴더 구조는 다음과 같이 된다.
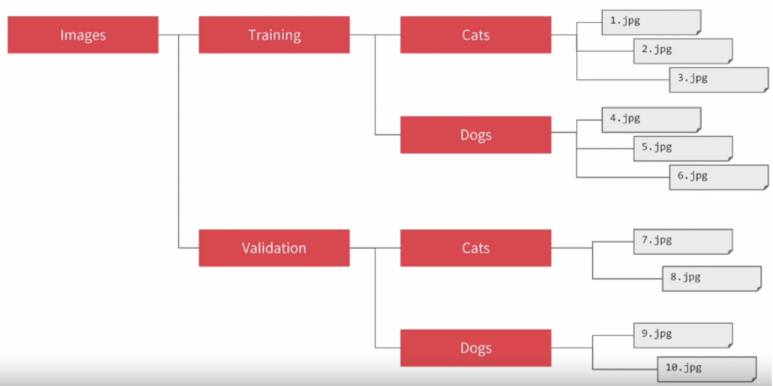
ImageDataGenerator는 자동으로 cat folder 안에 있는 데이터에 cat label을 붙이고, dog folder 안에 있는 데이터는 dog label을 붙인다. 이 방식으로 데이터는 neural network에 넘어갈 준비가 완료된 것이다.
_MODEL CREATION
이제 VGG16 model을 만들어 보자
1) Convolution 단계

먼저 모델이 Sequenctial model임을 설정하고 차례대로 layers를 추가한다.
1개 block을 다음과 같다고 할 때,
- 2개의 Convolutional Layer (처음 kernel 수 : 64, kernal size : 3x3, zero padding, 활성화 함수 : ReLU)
- 1개의 Maxpool Layer (pool size: 2x2, stride : 2x2)
2개 block을 적은 것이 위 코드이다. 유일하게 바뀌는 것은 이전 단계의 MaxPooling으로 인해 증가하는 filter(kernel) 수이다.
- padding = "same" : zero padding을 의미한다. padding = "valid"일 경우 no padding.

1개 block:
- 3개의 Convolutional Layer (kernel 수: 256개, kernel size : 3x3, zero padding, ReLU 활성화 함수)
- 1개의 MaxPool Layer (앞과 동일)
3개의 block을 나타낸 것이 위 코드이다. 여기서도 filter수는 2배씩 증가한다. 마지막 block에서는 그 전 필터 수로 유지된다.
- ReLU activation : 모든 음수값들이 다음 층으로 넘어가지 않게 한다.
2) Flatten -> Fully-connected Layer

모든 convolutional layer을 생성했으면, 이때까지 얻은 vector를 flatten해주고 Dense layer에 데이터를 넘겨준다.
- 2개의 Dense Layer (4096개 units)
- 1개의 Dense Softmax Layer (2개 Units)
마지막 층의 unit 수는 최종 분류되는 class 수와 같으므로, 나 같은 경우에는 ECG 신호가 5개의 class로 분류되니까 units = 5로 설정해야 한다.
- softmax : 이미지가 어떤 class에 속하는지 보여주는 confidence에 따라 0과 1 사이의 값을 출력한다.
추가로, units가 너무 많을 경우 과적합을 방지하기 위해 Drop-out을 넣을 수가 있다.
- Dropout(제거할 비율) : parameter가 너무 많을 경우, 학습 세트에 대한 모든 예측을 외워버려 정작 test set에서는 정확도가 떨어지는 과적합이 발생할 수 있다. 이와 같은 상황에서 unit의 수를 줄여서 모델을 단순하게 만드는 dropout을 사용할 수 있다. unit의 개수를 줄이면 그만큼 학습되는 parameter 수가 줄어들고, 모델은 적은 수의 parameter로도 예측을 잘 수행하기 위해 더 일반적인 특징으로 test set을 예측하게 된다. 이로서 train set에서 성능은 조금 낮아질 수 있지만, test set에서는 정확도를 높일 수 있다.
- 지정된 비율만큼의 유닛을 누락시켜 data 0으로 만들어준다.
3) Optimizer & Compile

여기서는 optimizer를 선택해야 한다.
Train data set을 이용하여 모델을 학습할 때, 최대한 틀리지 않는 방향으로 학습해야 한다. 여기서 얼마나 틀리는지가 '손실(loss)'를 나타내며, 이를 알게 하는 함수가 loss function (손실함수)이다.
우리는 이 손실함수의 최소값을 찾는 것을 학습의 목표로 하는데, 이 과정을 최적화 (Optimization)이라 하고, 이를 수행하는 알고리즘이 최적화 알고리즘 (Optimizer)이다.
이해하기 쉽게 일상 생활 예를 들어보면, 등산을 하고 정상에서 지도나 앱 없이 하산을 할 때, 우리는 가장 빠른 길을 찾기 위해 옆으로 돌아가기 보다 고도가 낮은 쪽으로 나아가려고 할 것이다. 결국 한발 이동할 때 마다 고도가 낮아지고 있다면 가장 빠르게 하산할 수 있게 되는데, 이 원리가 optimzer의 원리와 같다.
Optimizer 종류는 다음과 같은데, project에는 현재 가장 많이 사용되는 Adam을 사용해 보았다. (Optimizer도 project 성격에 맞게, 모델에 맞게 선택해야 한다). Optimizer에 대한 자세한 내용은 따로 포스팅 해야겠다.
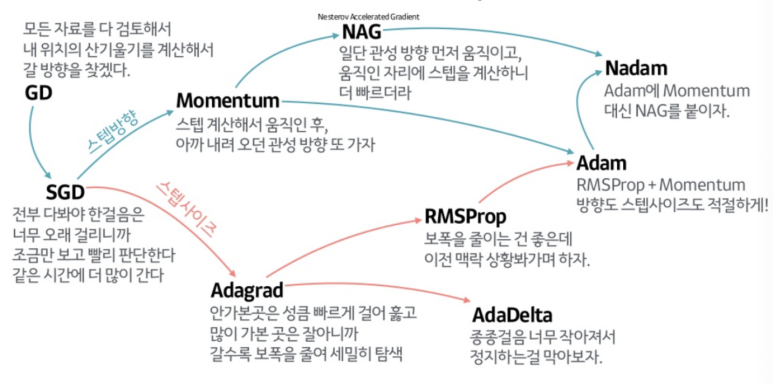
- Adam (lr = 0.001, beta_1 = 0.9, beta_2 = 0.999)
앞서 보여준 방법은 model = Sequential( ) 이후 층을 하나씩 추가하는 단순한 방법이었는데,
좀 더 나아가서 input함수를 이용하여 다음과 같이 깔끔하게 정리할 수 있다. 이 두번째 방법을 더 많이 사용하는 것 같다.
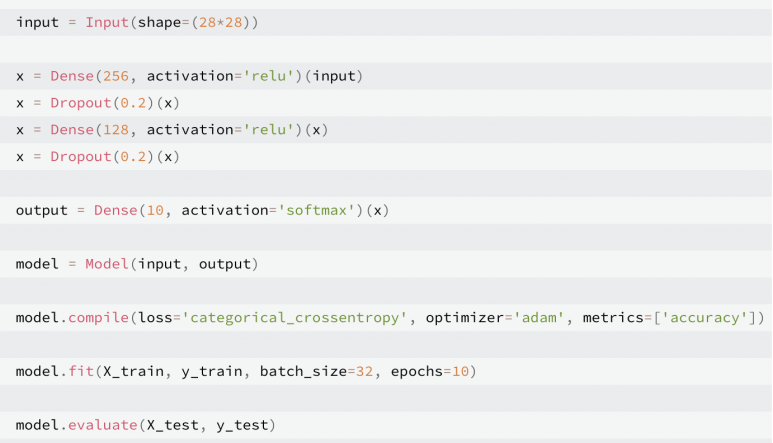
- epochs :
- epoch란 인공 신경망에서 전체 데이터에 대해서 순전파와 역전파가 끝난 상태를 말한다. 전체 데이터를 하나의 문제지에 비유한다면 문제지의 모든 문제를 끝까지 다 풀고, 정답지로 채점을 하여 문제지에 대한 공부를 한 번 끝낸 상태를 말한다.
- 만약 epoch가 50이라고 하면, 전체 데이터 단위로는 총 50번 학습한다 (문제지에 비유하면 문제지를 50번 푼 셈)
- epoch 횟수가 지나치거나 너무 적으면 앞서 배운 overfitting과 underfitting이 발생할 수 있다.
- batch_size :
- batch size는 몇 개의 데이터 단위로 매개변수를 업데이트 하는지를 말한다.
- 문제지에서 몇 개씩 문제를 풀고나서 정답지를 확인하느냐의 문제이다. 사람은 문제를 풀고 정답을 보는 순간 부족했던 점을 깨달으며 지식이 업데이트 되지만, 기계 입장에서는 실제값과 예측값으로부터 오차를 계산하고 optimizer가 매개변수를 업데이트 한다. 여기서 중요한 포인트는 업데이트가 시작되는 시점이 정답지/실제값을 확인하는 시점이라는 것이다.
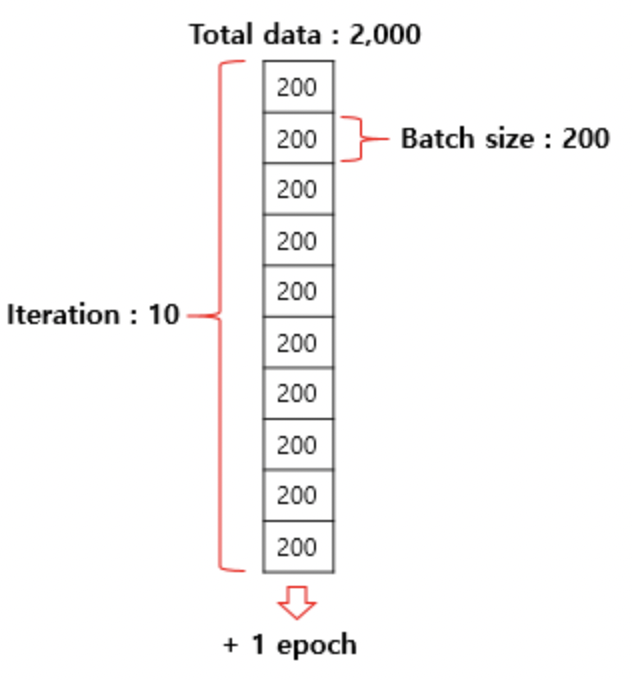
- 사람이 2,000 문제가 수록되어있는 문제지의 문제를 200개 단위로 풀고 채점한다고 하면 이때 배치 크기는 200이다. 기계는 배치 크기가 200이면 200개의 샘플 단위로 가중치를 업데이트 한다.
- 여기서 주의할 점은 배치 크기와 배치의 수는 다른 개념이라는 것이다. 전체 데이터가 2,000일때 배치 크기를 200으로 준다면 배치의 수는 10이다. 이는 에포크에서 배치 크기를 나눠준 값(2,000/200 = 10)이기도 하며, 이때 배치의 수를 iteration이라고 한다.
- batch size가 클수록 많은 데이터를 저장해두어야 하므로 용량이 커야 한다. 하지만 batch size가 작으면 학습은 촘촘하게 되겠지만 계속 label과 비교하고 가중치를 업데이트 하는 과정을 거치기때문에 시간이 오래 걸린다.
- iteration (=step)
- iteration이란 한 번의 에포크를 끝내기 위해서 필요한 배치의 수를 말한다 (또는 한 번의 에포크 내에서 이루어지는 매개변수의 업데이트 횟수)
- 전체 데이터가 2,000일 때 배치 크기를 200으로 한다면 이터레이션의 수는 총 10이다. 이는 한 번의 epoch 당 매개변수 업데이트가 10번 이루어진다는 것을 의미한다.
- iteration은 Step이라고 부르기도 한다.
4) Model summary

생성된 모델의 계층과 훈련 가능한 parameters 수를 확인할 수 있다.

_TRAIN THE MODEL
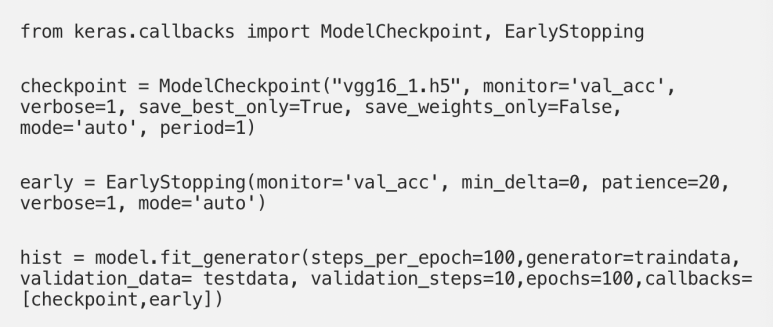
- ModelCheckpoint : 모델을 disk에 저장할 파일 명을 입력해 주면 나중에 다시 모델을 훈련할 필요 없이 불러낼 수 있다.
- EarlyStopping : 모니터링하도록 설정한 변수가 더 이상 개선되지 않으면 훈련을 멈추도록한다. 여기서는 monitor = 'val_acc'로 설정하여 test set의 정확도를 모니터링 하고 있고, patience = 20 로 하여 epoch 20회차 동안 val_acc점수가 올라가지 않으면 모델 학습을 중단하게 되어있다.
- model.fit_generator : ImgaeDataGenerator를 사용한 경우 fit_generator로 학습한다.
내가 다루는 data는 image data가 아닌 DataFrame이기 때문에 modle.fit_generator 대신 model.fit을 사용했다.
model을 fitting할 때 설정하는 변수로 앞서 다룬 batch_size와 epochs가 있었는데, 이 둘을 어떻게 설정하느냐에 따라 모델의 성능이 바뀌기 때문에 가장 효율적인 수를 찾아야 했다.
조사하다가 이에 관련한 실험을 한 논문을 발견했고, 실험 결과 다음과 같이 나왔다.
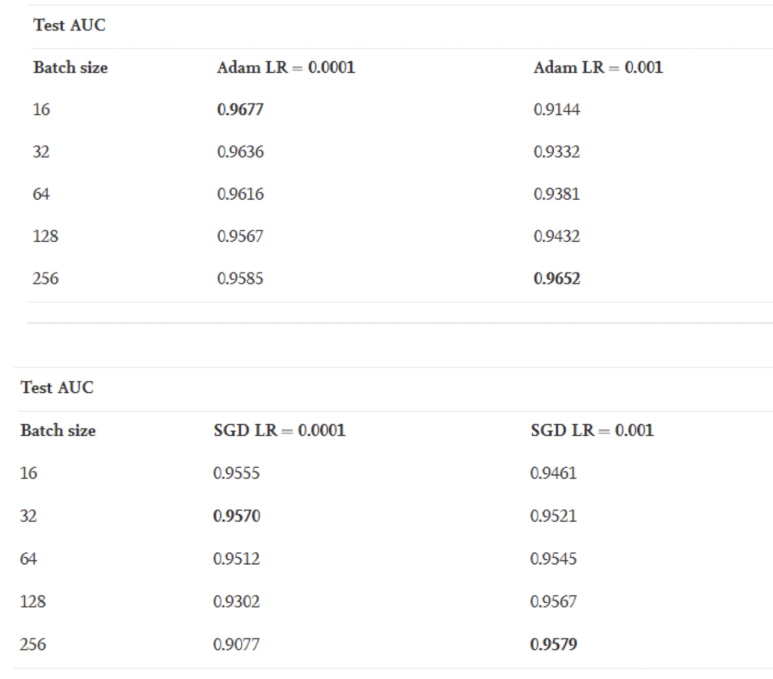
따라서 나는 batch_size = 256, lr = 0.001을 사용해 보았다. (batch_size=16을 해버리면 시간이 오래 걸릴 수도 있다.)
1차 시도
정확도가 0.9 이상 나오긴 했지만, class 0에 대해서만 점수가 나오고 나머지 class는 모두 0이 나왔다...
내 데이터는 데이터 사이즈가 매우 크고, 불균형한 데이터인데 다시 oversampling을 해본 후 돌려봐야겠다.
2차 시도
ADASYN으로 oversampling 후 model을 train 시켰는데 정확도가 around 0.7로 매우 낮게 나왔다.
교수님께도 여쭤보고 따로 찾아본 내용에 따라 정확도에 영향을 주는 부분들 ( batch_size, lr, epochs 등) 을 수정하여 0.98 로 높였다!!!
_REF
https://towardsdatascience.com/step-by-step-vgg16-implementation-in-keras-for-beginners-a833c686ae6c
'AI Learner > DL' 카테고리의 다른 글
| [BoostCourse DL] 3.2 Optimization_Regularization (0) | 2023.04.06 |
|---|---|
| [BootCourse DL] 3. Optimization_Gradient Descent Methods (0) | 2023.04.06 |
| [BoostCourse DL] 2. Neural Network, MLP (0) | 2023.04.03 |
| [BoostCourse DL] 1. Start (0) | 2023.04.03 |
| [CNN] VGG16 model (0) | 2023.04.03 |


